Topic Modeling produces a topic representation of any corpus’ textual field using the popular LDA model. Each topic is defined by a probability distribution of words. Conversely, each document is also defined as a probabilistic distribution of topics.
In CorText Manager, a topic model is inferred given a total number of topics users have to define. The composition of topics is accessible using the library pyLDAvis (see below how to cite this work) allowing to visualize the most relevant words fitting in each topic. Topics are positioned in 2d according to their distances using a multidimensional scaling algorithm. The script also produces a new table storing the assignments of topics to documents. The distribution is flattened such that each document is assigned to topics it is already linked to with a probability superior to the inverse number of topics.
The linguistic processing can be customized in the second panel. It’s quite straightforward. Be aware that by default Snowball Stemmer is the algorithm used for stemming.
Additionally one can modify the number of iterations which can be helpful if your corpus is small. It is also possible to set the document-topic density prior to asymmetric (which is usually advised https://rare-technologies.com/python-lda-in-gensim-christmas-edition/) or to auto if needed.
Finally a graph is also produced showing the evolution of perplexity and log likelihood.
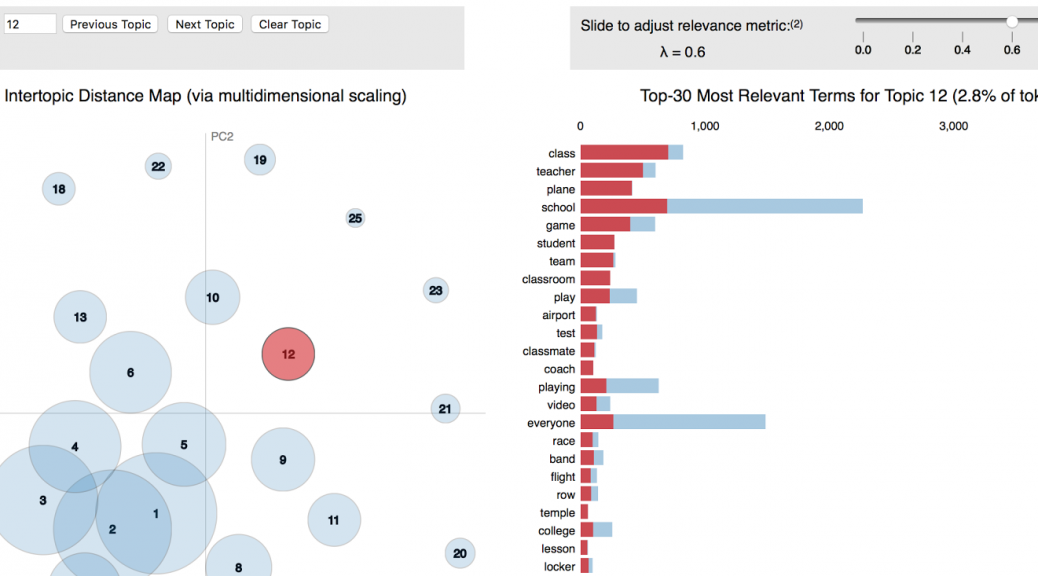
An example of outcome is shown using a dream dataset (data courtesy of dreamscloud):
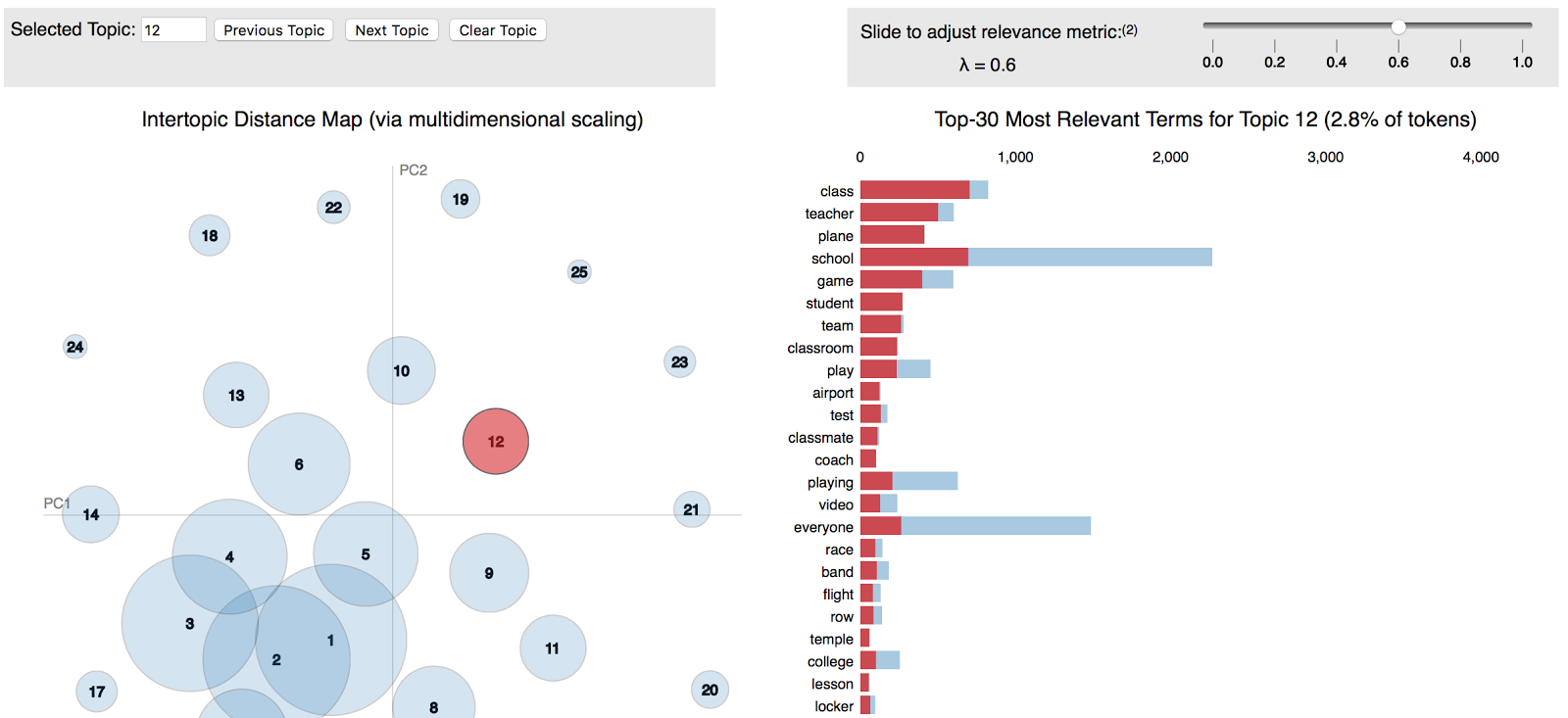
Access the dynamic version of the above image by clicking this here! Where saliency for topics (Chuang et. al, 2012) and relevance for terms (Sievert & Shirley, 2014) are computed.
Topic Modeling parameters
Data Description
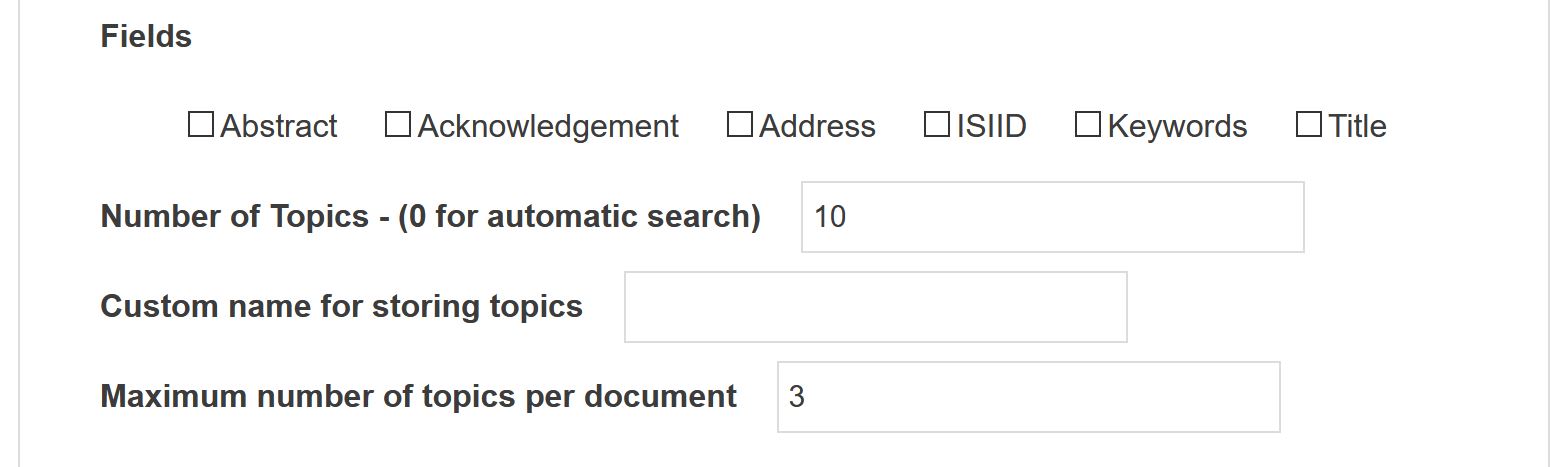
Fields
Field used for analysis
Number of Topics
Number of topics you define, which will be determine the makeup of the analysis. If you type 0, then the optimal number of topics will be assessed optimizing over the number of topics which would produce the model with the highest topic coherence possible. You will still be required to set the minimum and maximum number of topics over which the optimization is made (as well as the resolution of the search interval)
Custom name for storing topics
Indicate a custom name to identify the resulting variable.
Maximum number of topics per document
Only the n most prevalent topic per document will be stored.
Text Cleaning Parameters
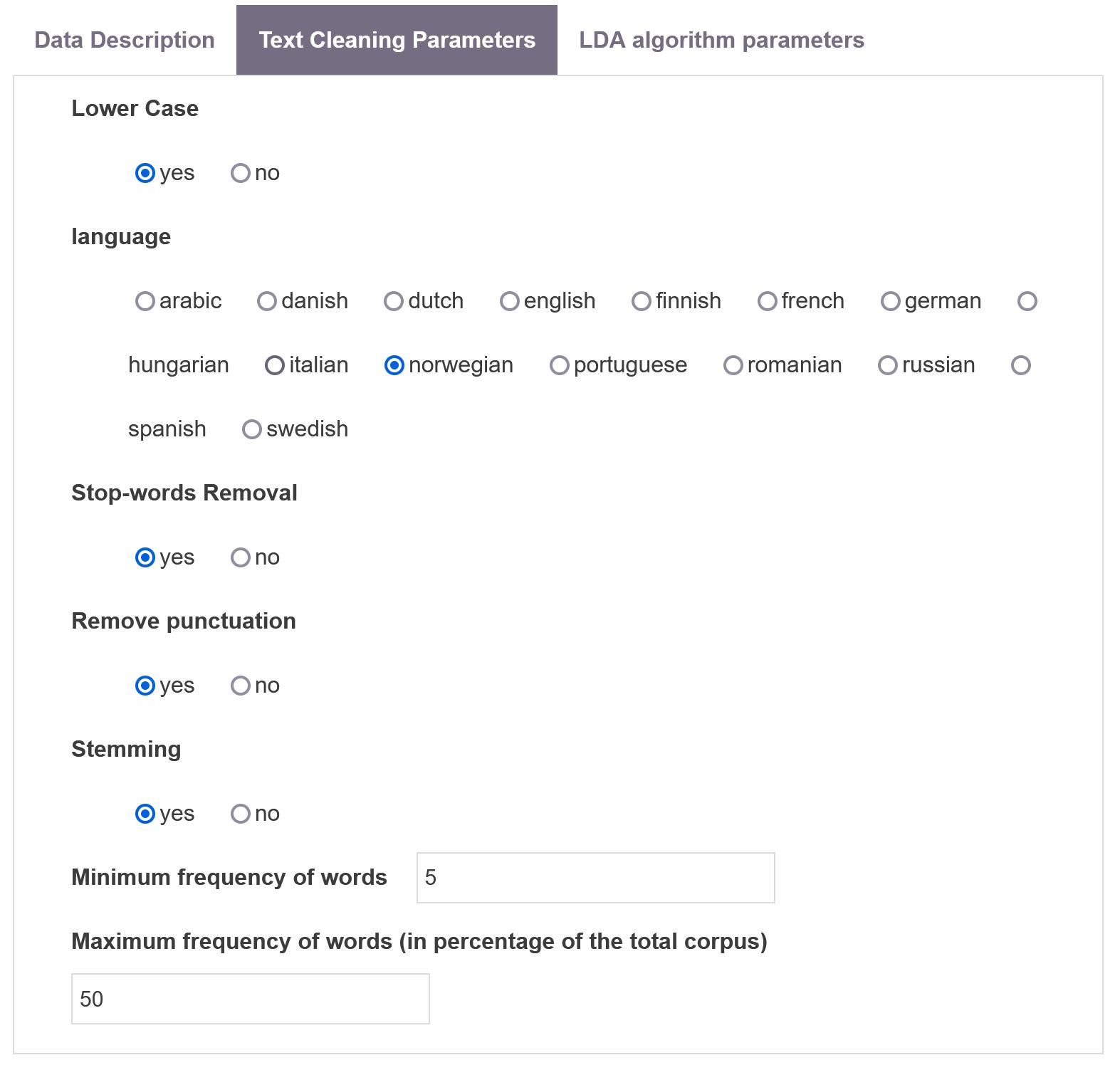
Lower Case
Will keep all label names as lower case
language
Select language if stemming or/and stop word removal is active.
Stop-words Removal
Will remove stop words, including words like “the”, “and” or “be” in the selected language . These are high-frequency grammatical words which are usually ignored in text retrieval applications. See here for the list of stop-words per language.
Remove punctuation
Remove punctuation.
Stemming
This option will trigger the script to return the basic form of a word (M. Porter, 1980). This may help avoid orthographically different words which are actually the same. Only working if the original language you are working with is listed.
Minimum frequency of words
Threshold for the words in the vocabulary defined by number of occurrences.
Maximum frequency of words
This parameter will discard any word which overall frequency in the corpus is above the indicated percentage (useful to get rid of uninformative very frequent words).
References
- Sievert C. & Shirley KE., LDAvis: A method for visualizing and interpreting topics, Proceedings of the Workshop on Interactive Language Learning, Visualization, and Interfaces, pages 63–70, Baltimore, Maryland, USA, June 27, 2014.c
- Jason Chuang, Christopher D. Manning, Jeffrey Heer, Termite: Visualization Techniques for Assessing Textual Topic Models, In Proceedings of the International Working Conference on Advanced Visual Interfaces, pages 74-77, 2012
- Porter, M. “An algorithm for suffix stripping.” Program 14.3 (1980): 130-137.
- More information on the package used in CorText Manager: https://pyldavis.readthedocs.io/en/latest/readme.html#usage
 Cortext Manager Documentation
Cortext Manager Documentation