
Cortext Manager proposes a full ecosystem of modeling and exploratory tools for analyzing data, which can be more or less calibrated. A wide range of data formats can be imported into Cortext Manager, leaving you great flexibility in terms of data type that can be processed.
Cortext Manager is particularly adapted for processing text: corpora made of scientific publications, press articles or coming from social networks, collected from various databases and applications (e.g. Scopus, Web Of Science, Europress, Twitter…) are typical data analyzed by users’ community. Cortext Manager accepts and processes data extracted from this kind of applications (see the complete list below) but also data contained in simple text files (i.e. in pdf, txt or docx formats) and any king of data formatting in csv, xls, json or RIS files.
Read this page for more details about the correct formatting of data (depending on the original source of the data or the type of format of your files) for being able to integrate them in Cortext Manager.
Once your data has been collected/structured (whatever the source/format), you should zip the file(s) that compose your corpus into a single zip archive before you can upload it into Cortext Manager (see Upload corpus section). The first step is then to use “Data Parsing” script which restructures the imported data into a sqlite database, then allowing you to apply analyses (see Data parsing section).
Ready-made sources (data exported from existing databases and applications)
Cortext Manager allows you to import data directly extracted from certain databases or applications, as specific parsers are proposed for these sources. These parsers are able to filter data and to do some pre-processing in order to keep only useful data and metadata (e.g. authors, journal…) and to make them analyzable (e.g. authors’ addresses present in Web Of Science export will be restructured into several variables in the sqlite database created by Cortext Manager (i.e. institution, city, country) making the data directly processable). Variables are usually renamed by Cortext Manager: you will find easily understandable names in the sqlite database created after applying the parsing script and when choosing fields/parameters in analysis scripts.
Find here the data sources automatically supported by Cortext Manager and the options to choose when exporting raw data. Please note that for most databases/applications a maximum number of records can be exported in one download. Depending on your query, you may have to repeat the export step several times, your data will then be split into several files. Cortext Manager is able to automatically compile information coming from these different files.
Scientific bibliography databases
Web of Science
To build a corpus from Web Of Science:
-
- Access to the Web of Science platform website
- Enter your query, click on “Search” button, which will take you to the results page containing the data export features
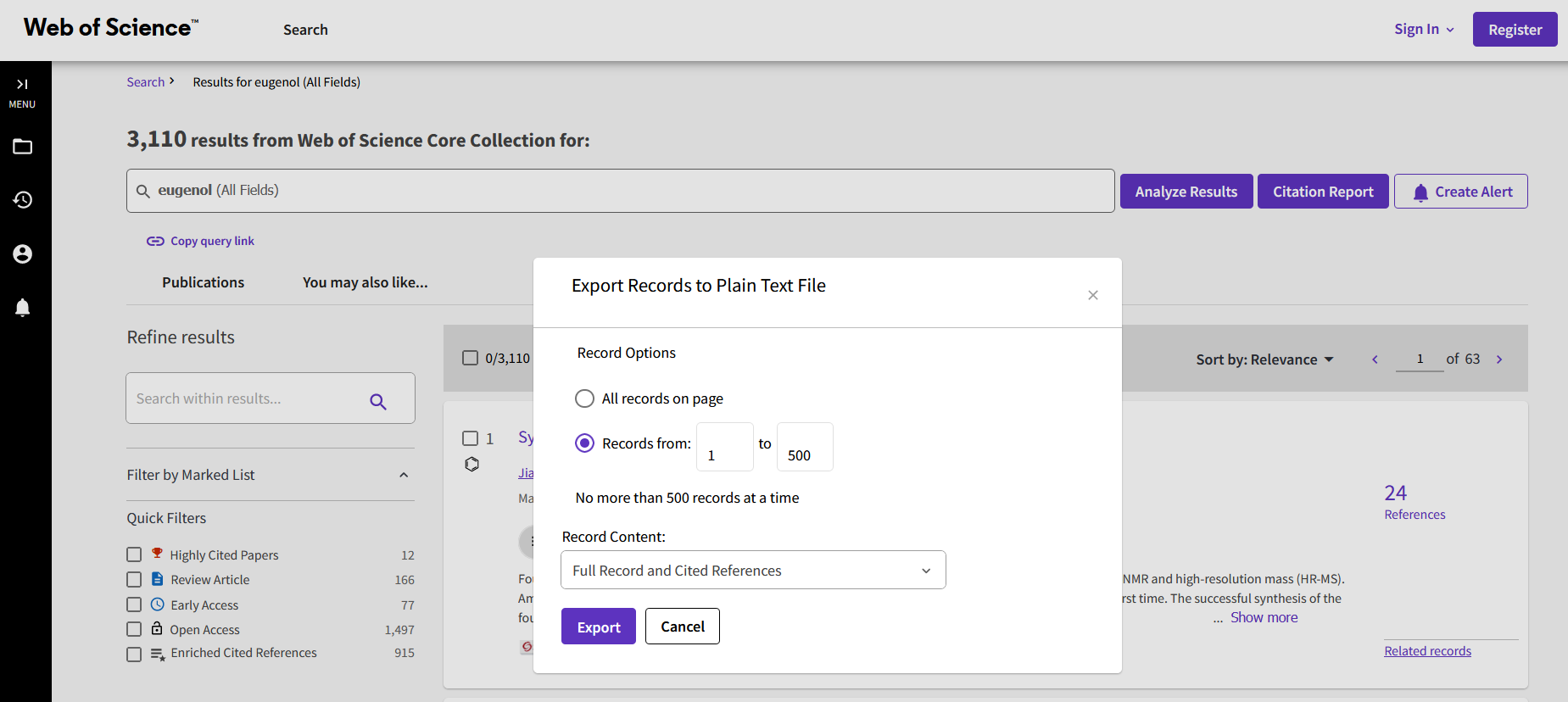
- Click on “Export” button, select “Plain text file” from the drop-down menu
- In the opened window, select the option “Records from” and the entry “Full Record and Cited References” in the “Record Content” drop-down menu. Note that you can export only 500 results for each download
- Click on “Export” to obtain the data .txt file
- Zip the file(s)
When using “Data Parsing” script, you should choose the “isi” entry in the “Corpus Format” drop-down menu.
Scopus
To build a corpus from Scopus:
- Access to the Scopus platform website
- Enter your query, click on “Search” button, which will take you to the results page containing the data export features
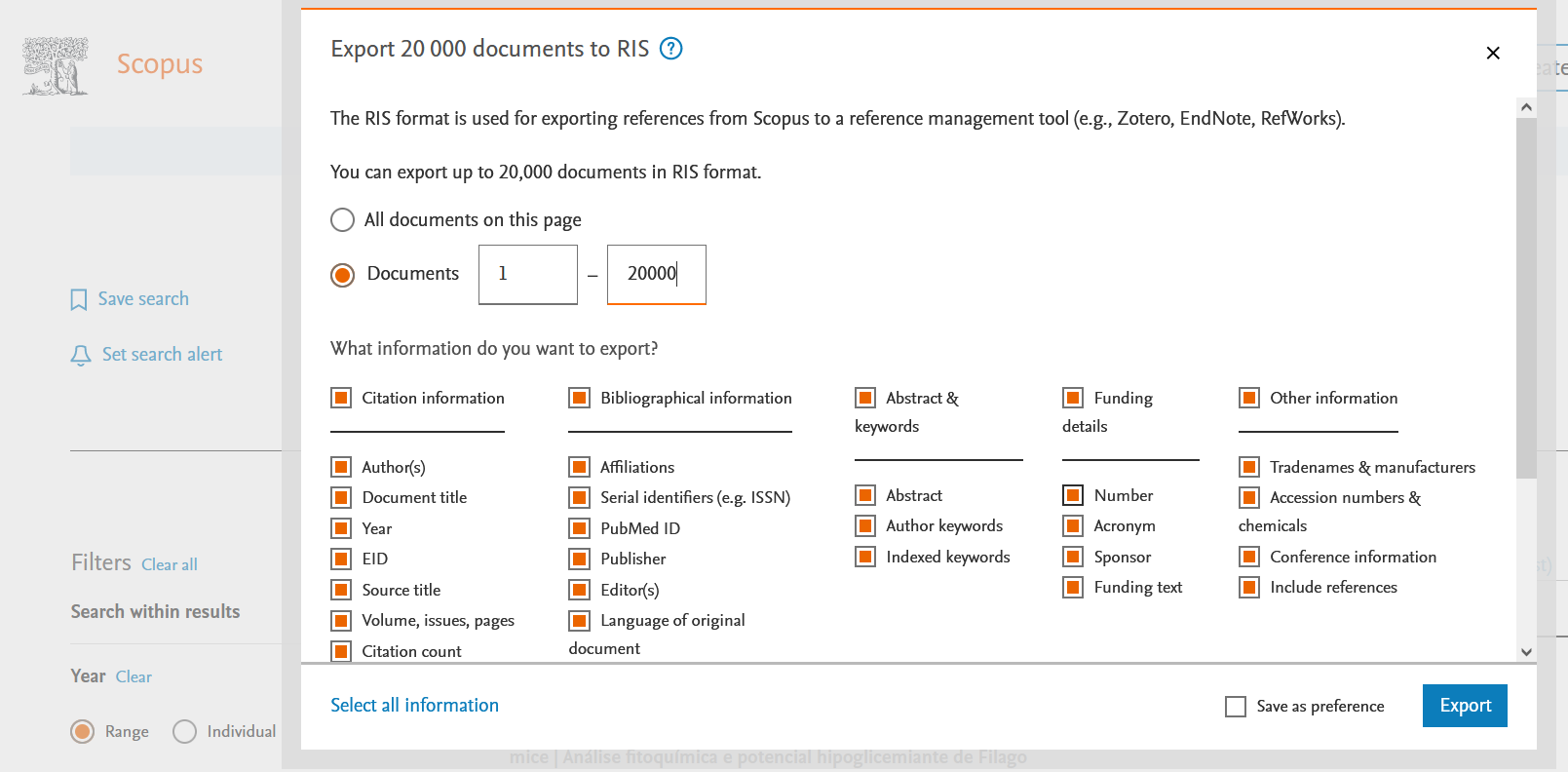
- Click on “Export”, select “RIS” as file types in the drop-down menu
- In the opened window, select the option “Documents” and click on the option “Select all information” in the “What information do you want to export” part of the window. Note that you can export only 20 000 results for each download
- Click on “Export” to obtain the data .RIS file
- Zip the file(s)
When using “Data Parsing” script, you should choose the “ris (scopus)” entry in the “Corpus Format” drop-down menu (using “ris (scopus)” compare to the basic “ris” format will enable Cortext Manager to run more complex pre-processing steps to build useful variables ready to be used in your analyses).
Pubmed
To build a corpus from Pubmed:
- Access to the Pubmed platform website
- Enter your query, click on “Search” button, which will take you to the results page containing the data export features
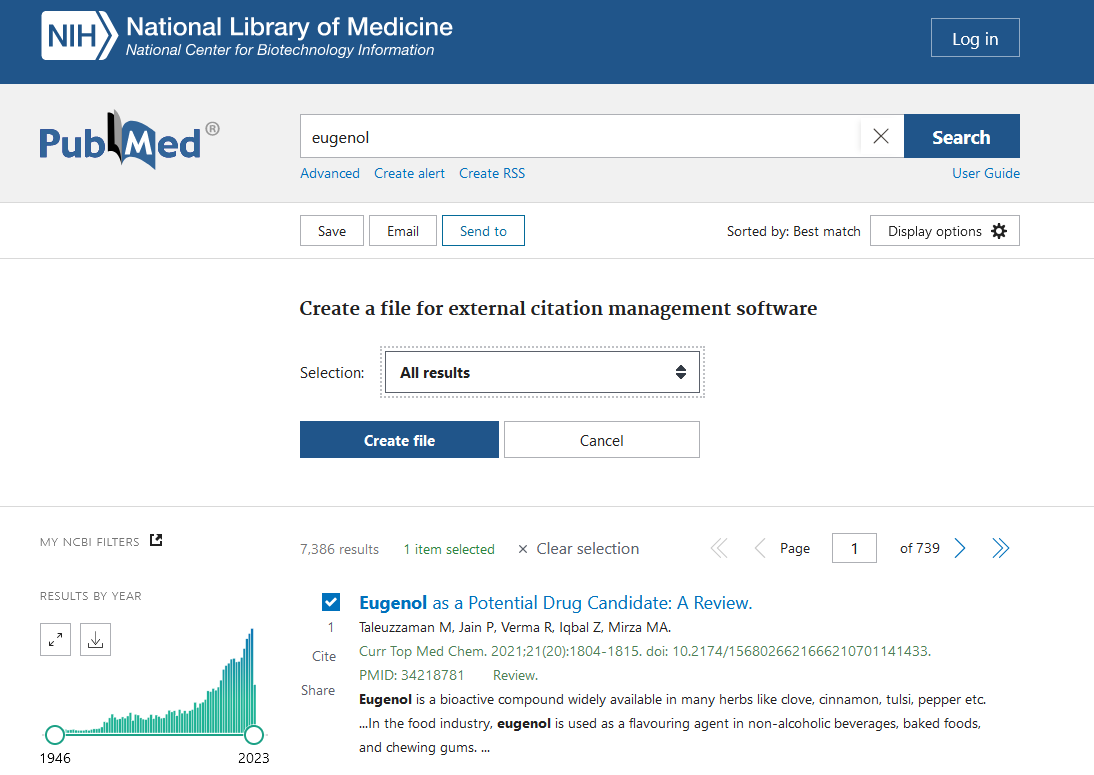
- Click on “Send to” and select “Citation manager” in the drop-down menu
- In the opened window, select the option “All results” and click on the “Create file” button to obtain the data .nbib file. Note that you can export only 10 000 results for each download
- Zip the file(s)
When using “Data Parsing” script, you should choose the “nbib” entry in the “Corpus Format” drop-down menu.
In case you have an old corpus downloaded in an .xml format (option available in the previous version of the Pubmed platform), it is still possible to integrate it into Cortext Manager by using the “xmlpubmed” entry as “Corpus Format” (see Depreciated source paragraph below).
Istex
ISTEX is a retrospective digital archive of science, a service that provides access to a very large and rich collection of full text scientific articles, covering all disciplines and spanning over 700 years.
Cortext manager lets you work directly with corpora downloaded from the ISTEX platform: it will treat and extract information from the different files included in the downloaded archive (“.zip”). Notably, it extracts the full text of items, and the main metadata such as: title, abstract, date, journal or monographs (books and volumes), authors’ name, authors’ affiliation (addresses and countries), language, doi of the publication, and ISTEX IDs.
Note that ISTEX may provide both an original and a “cleaned” versions of the full text. In that case, Cortext manager automatically selects from the dropped zip the cleaned version, if available. The full text is recorded in the Cortext database under the field “body_text”. The source of the text is recorded in the “body_text_source” field, and in case a clean version was found it will be {“file”: “cleaned”, “format”: “txt”}.
Together with the metadata and full text, ISTEX also provides results of its own term extraction procedure, from which Cortext Manager will produce a file named “teeft_terms.tsv”. This file contains terms extracted from the corpus, together with frequency and specificity values. The extraction is based on the software Teeft, and indexes exclusively English full text on a document-level basis. The file “teeft_terms.tsv” therefore only contains data for the part of your corpus in the English language.
To build a corpus from ISTEX data:
- Access the ISTEX Search website
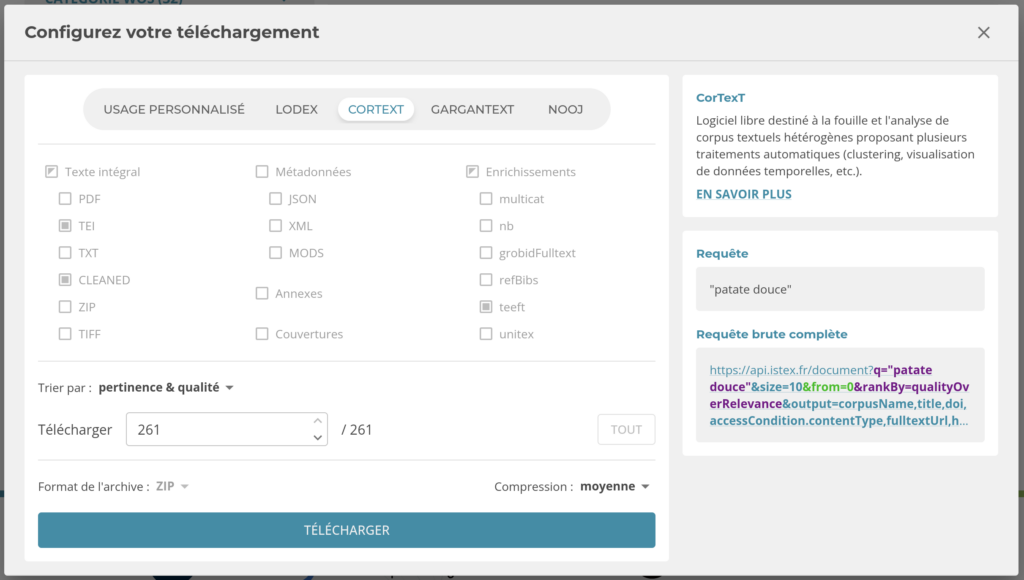
- Enter your query, and fill in the options for selecting the number and order of documents
- Scroll to the bottom of the page and choose “TÉLÉCHARGER LE CORPUS”
- Choose the target usage for the corpus as “CORTEXT”
- Download the archive file (“.zip”)
The zip should be parsed by selecting “istex” as the “Corpus Format” in the “Data Parsing” script.
Because ISTEX is a full text source, the datasets may be quite big, so parsing and analyses may take time to run.
Be careful that ISTEX provides access to varied sources of data, which requires a lot of data restructuring, cleaning and OCRization on their part, especially for older documents. Depending on the scope of your corpus, data quality and metadata availability may differ significantly between items, and you should carefully consider how to exploit the data.
Important information regarding parsing results may be present in Cortext’s “log file”, for one, the number of items where the full text was replaced by the clean version provided by ISTEX. We recommend you to check the log file of the parsing job once the database has been built.
PDFs of Scientific Articles
You can upload your own collection of scientific PDF articles and process them with the “Data Parsing” script using the “pdf (scientific articles – GROBID)” option. Cortext Manager will then rely on the GROBID machine learning library to extract structured information from the documents. The parser attempts to retrieve:
- Title
- Abstract
- Authors
- Author affiliations (institution, address, country)
- Journal
- Publication year
- Textual contents
- In-text citation markers
- DOI
- References (including authors, journal and titles of cited papers)
We recommend using this option only with scientific articles, as GROBID is designed specifically for this type of content and performs reliably in that context. Each PDF should contain a single article. Don’t forget to zip your PDF file(s) before uploading.
Press
Factiva
To build a corpus from Factiva:
- Access to the Factiva platform website
- Type your query and click on the “Search” button, which will take you to the results page containing the data export features
- Restrain your selection to “Publications” (i.e. you should stay on the “Publications” tab)
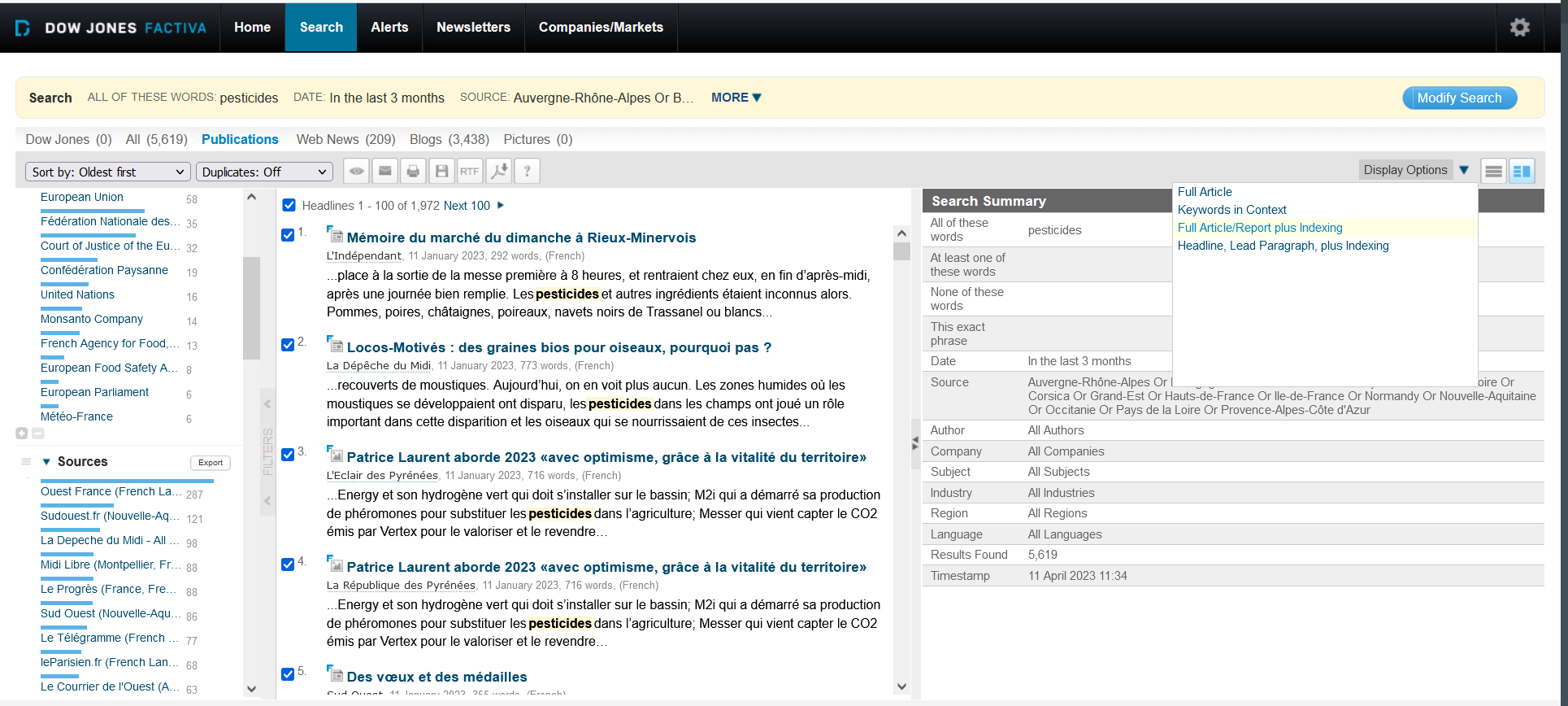
- Choose “Full Article/Report plus indexing” option in the “Display Options” drop-down menu (present at the top right part of the dashboard)
- Click on “Format for Saving” button and choose the option “Article Format” in the drop-down menu (don’t forget to tick the checkbox “Headlines…” to be able to save up to 100 results at each download).
- In the opening window containing the results, go to the menu and save the file (the format should be .html). Please verify that the result file present tag like in this example (the tags are present thanks to the selection of the option “Full Article/Report plus indexing” in the “Display options”)
- Zip the file(s)
When using “Data Parsing” script, you should choose the “Factiva” entry in the “Corpus Format” drop-down menu.
Among the fields you will find in the sqlite database created by Cortext Manager, the following will be especially useful for doing textual analyzes: “HeadLine” (which corresponds to the title of the article), “LeadParagraph ” (corresponds to the highlighted paragraph) and “Text ” (corresponds to the rest of the content), “article_fulltext ” (which simply concatenates the three parts in a single variable).
Europresse
To build a corpus from Europresse:
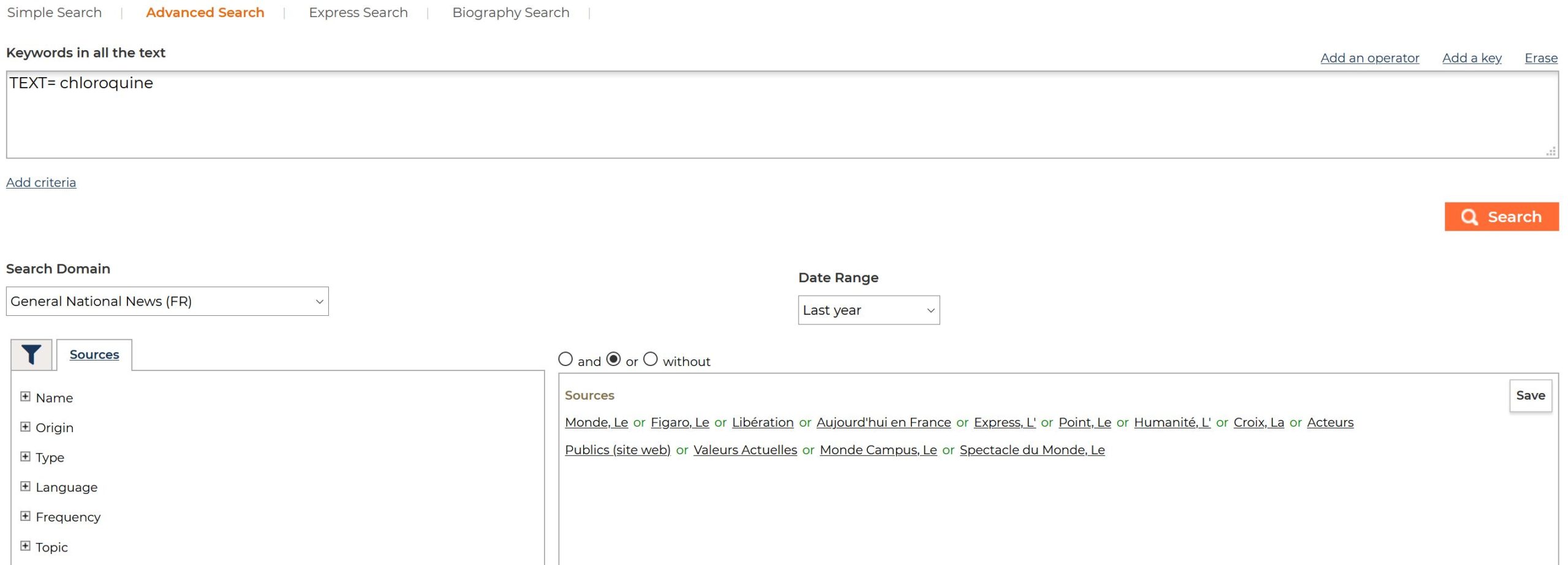
- Access to the Europresse platform website
- In the top menu bar, choose the “Classic version” of the site
- Choose “Advanced Search”, build your query, and click on “Search” button, which will take you to the results page containing the data export features
- Restrain your selection to “Press” (i.e. you must unclick all the other tabs, “Television and Radio”, “Social Media” …)
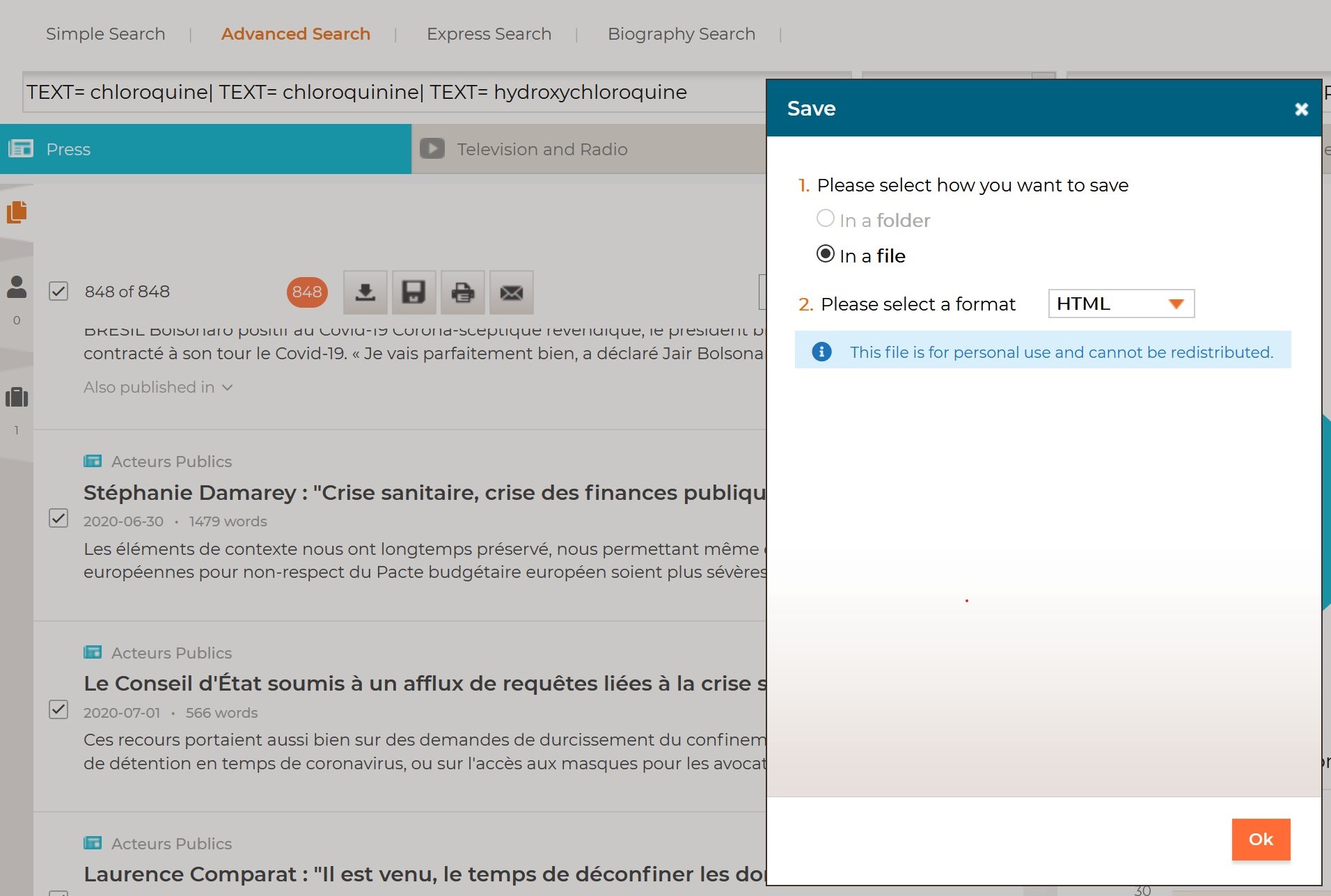
- Scroll down the articles list to select all articles that correspond to one batch. Note that you can export only 1 000 results for each download.
- Click on “Save” button and choose HTML as export format
- Zip the file(s)
When using “Data Parsing” script, you should choose the “Europresse” entry in the “Corpus Format” drop-down menu.

Lexis Nexis files
Lexis Nexis data should be downloaded as simple text files. Simply zip the batch of 500-records you need to start your analysis. For the moment, time information is automatically transformed into months since January 1990.
Social networks
Twitter json files
A specific parser is provided for data collected through the Twitter search API (using tweet_mode=’extended’). You can then define a time granularity that goes from the year to the second. Only the most pertinent information from the API are conserved. Besides the original fields (like lang, user_name, or entities_hashtags) some additional fields are built: htgs, urls, usme, symbol. They simply correspond to the hashtags, urls, user mentions, and symbols present in a tweet. But a retweet, then original information about the original version are added.
Generic formats
You also have the possibility to format your data by yourself. Cortext Manager accepts different file formats. Find them and see how to build them in this part.
For this type of files (except for text documents – pdf, txt, docx), each variable contained in your original files will be recorded in its own table in the sqlite database built by the “Data Parsing” script, and the original names will be used as table names. You will then find all these variables and their original names when choosing fields/parameters in analysis scripts.
Please avoid using “Terms” and “ISITerms” as variable names in your own custom files, as theses names are protected by Cortext Manager.
Csv
You have the possibility to create your own corpus composed of one or several csv files. Data should be structured as follows:
- each column should correspond to the data of one variable and should be entitled (i.e. in the first line of the file) with the variable name (please don’t use special characters for variable names).
- each line should correspond to the data of one record (e.g. a document, an article, a patent…)
- if some of your variables are hosting multiple items (e.g. several authors), then simply separate the information with 3 successive stars: ***
- if certain of your variables have multiple embedded values (e.g. depending of how you structure your data, it can be the case for authors’ addresses which can have 3 levels: street, city and country), please indicate the secondary intra-field separator: |&|
- if you have a time field, the data must be formatted either as integers (e.g. 2023) either following the classic time format: Y-m-d (2001-12-23, being December 23rd 2001 for instance)
Different options regarding .csv file formatting (e.g. choice of separator…) are proposed in the “Data Parsing” window of Cortext Manager. However, to stay on the safe side, it is better to comply with these default formatting options when saving the .csv file:
- “tabulations” as field separator
- no quote for textual fields
- with the UTF-8 encoding option (essential to preserve specific characters as accents in your data)
LibreOffice offers a convenient interface to make sure your dataset is in the desired format. Google Sheet is also convenient for that purpose (simply choose .tsv format to export).
See this example (source : patents data) as a typical csv file.
Note that your corpus can be made up of several csv files. However, in that case, all the data related to one record (e.g. a document, an article, a patent…) must be within the same csv file (as Cortext Manager does not detect record’s identifiers from one file to another). Please name the columns (first row) the same way from one file to another, so that the data compiles for each of your variables.
Eventually, don’t forget to zip your csv file(s) and use the “robust csv” entry as “Corpus Format” when launching the “Data Parsing” script.
The following video illustrates step-by-step how to prepare a readable csv file for Cortext Manager:
RIS
RIS (Research Information Systems) is a standardized tag format made to store bibliographic data. If you are using citation management applications such as RefWorks, Zotero, Papers, Mendeley or EndNote, you can easily build exports in a RIS format. Google Scholar (RefMan for .ris), IEEE Xplore, the ACM Portal, ScienceDirect, SpringerLink and others are also offering this option to export selected articles.
If your corpus is coming from Scopus, please use the option made specifically for this source, “RIS (Scopus)”, when launching the “Data Parsing” script (this option enables Cortext Manager to run more complex pre-processing steps to build useful variables ready to be used in your analysis scripts).
Xls
You can create your own corpus composed of one or several xls files. To be able to parse your corpus, xls files should be structured as follows:
- each column should correspond to the data of one variable and should be entitled (i.e. in the first line of the file) with the variable name (please don’t use special characters for variable names).
- each line should correspond to the data of one record (e.g. a document, an article, a patent…)
- if some of your variables are hosting multiple items (e.g. several authors), then simply separate the information with 3 successive stars: ***
- if certain of your fields have multiple embedded values (e.g. depending of how you’re structure your data, it can be the case for authors’ addresses which can have 3 levels: street, city and country), please indicate the secondary intra-field separator: |&|
- if you have a time field, the data must be formatted either as integers (e.g. 2023) either following the classic time format: Y-m-d (2001-12-23, being December 23rd 2001 for instance)
When exporting spreedsheet from Excel Office, LibreOffice or Google Sheets, use the .xls format (Cortext Manager xls parser won’t work with .xlsx).
Note that your corpus can be made up of several xls files. However, in that case, all the data related to one record (e.g. a document, an article, a patent…) must be within the same xls file (as Cortext Manager does not detect record’s identifiers from one file to another). Please name the columns (first row) the same way from one file to another, so that the data compiles for each of your variables.
Eventually, don’t forget to zip your xls file(s) and use the “xls” entry as “Corpus Format” when launching the “Data Parsing” script.
Text files (.txt, .docx, .pdf)
You also have the possibility to import text files into Cortext Manager. They should be uploaded unmerged, meaning that each document/record should correspond to a unique file. Two fields will be created during parsing: “text” and “filename”. It is straightforward then to use corpus list indexer capacities to add some more metadata (like author, date, etc.) with the filename as a pivot key.
Don’t forget to zip your text file(s) and use the corresponding format option when launching the “Data Parsing” script (i.e. choose “txt” or “pdf” or “docx” entry).
Json
It is also possible to import simply formatted (with no embedded dictionnary) json files. You will be asked wether there is a time entry. Either formatted as integers, either following the classic time format: Y-m-d (e.g. 2001-12-23, being December 23rd 2001 for instance). Note that if time information is completed with T-h:m:s, it will be automatically ignored. You then can choose to transform time information into a certain number of years, months or days since January the 1st of any starting year you define.
Please use “json” entry and the source API “other” when launching the “Data Parsing” script.
Deprecated source (xml from Pubmed)
In case you have an old corpus in an xml format downloaded from the previous version of the PubMed platform, it is still possible to integrate it into Cortext Manager by using the “xmlpubmed” option as “Corpus Format” in the “Data Parsing” script window.
 Cortext Manager Documentation
Cortext Manager Documentation