Period Slicer allows users to customize the time periods according to which the corpus is analyzed.
Parameters
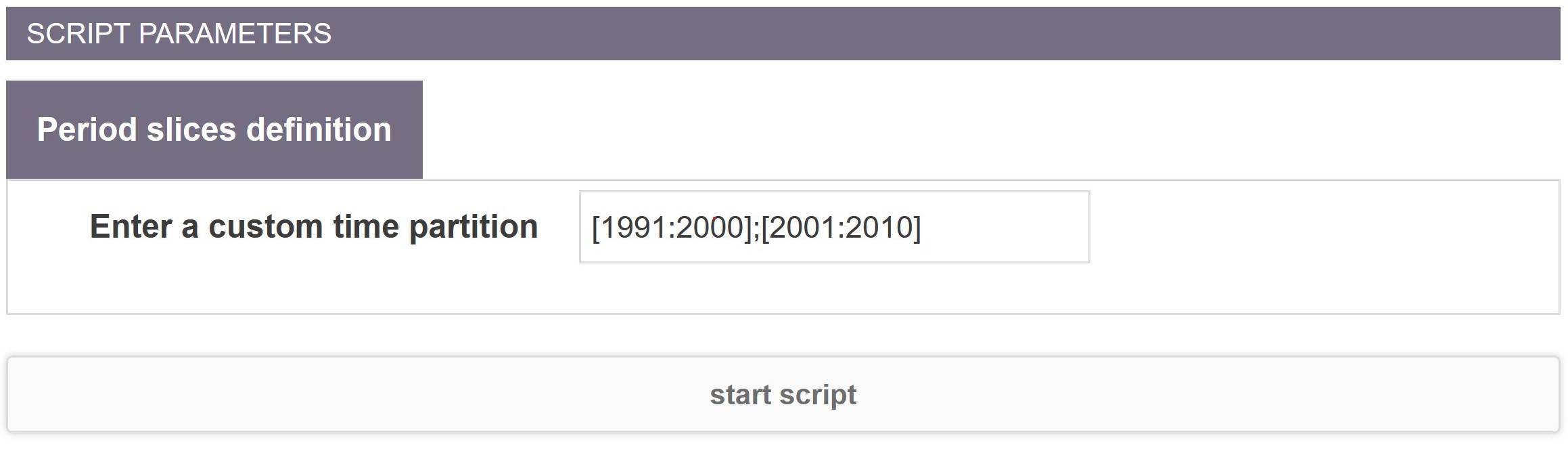
When launching Period Slicer, you need to input the different time periods which will be used to split the corpus. Each time period should be separated by semi-colons.
Lists of values
A time period is defined by a series of integer values (typically years) separated by commas and between brackets. For example [2010,2011];[2012,2013] will defines two time periods: one [2010,2011] and two [2012,2013].
Time ranges
Alternatively, you can use colons to define time ranges: [2010:2019] will define one time period ranging from 2010 to 2019 (included). You are also given the possibility to define overlapping time periods ex: [2000:2010];[2005:2015];[2010:2020].
Combination of lists and ranges
Commas and colons can be combined in the same time period. For example, [1990:2000];[2001:2005,2008];[2006:2007,2009:2011] defines 3 time periods: the first ranging from 1990 to 2000 the second from 2001 to 2005 plus 2008, the third gathers timesteps 2006,2007,2009, 2010 and 2011.
Period Slicer’s result
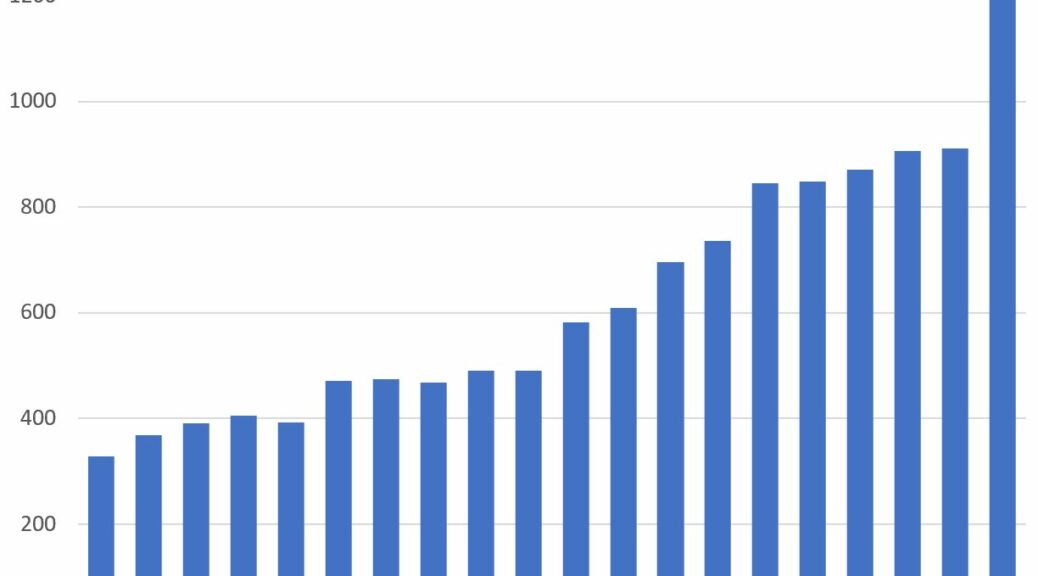
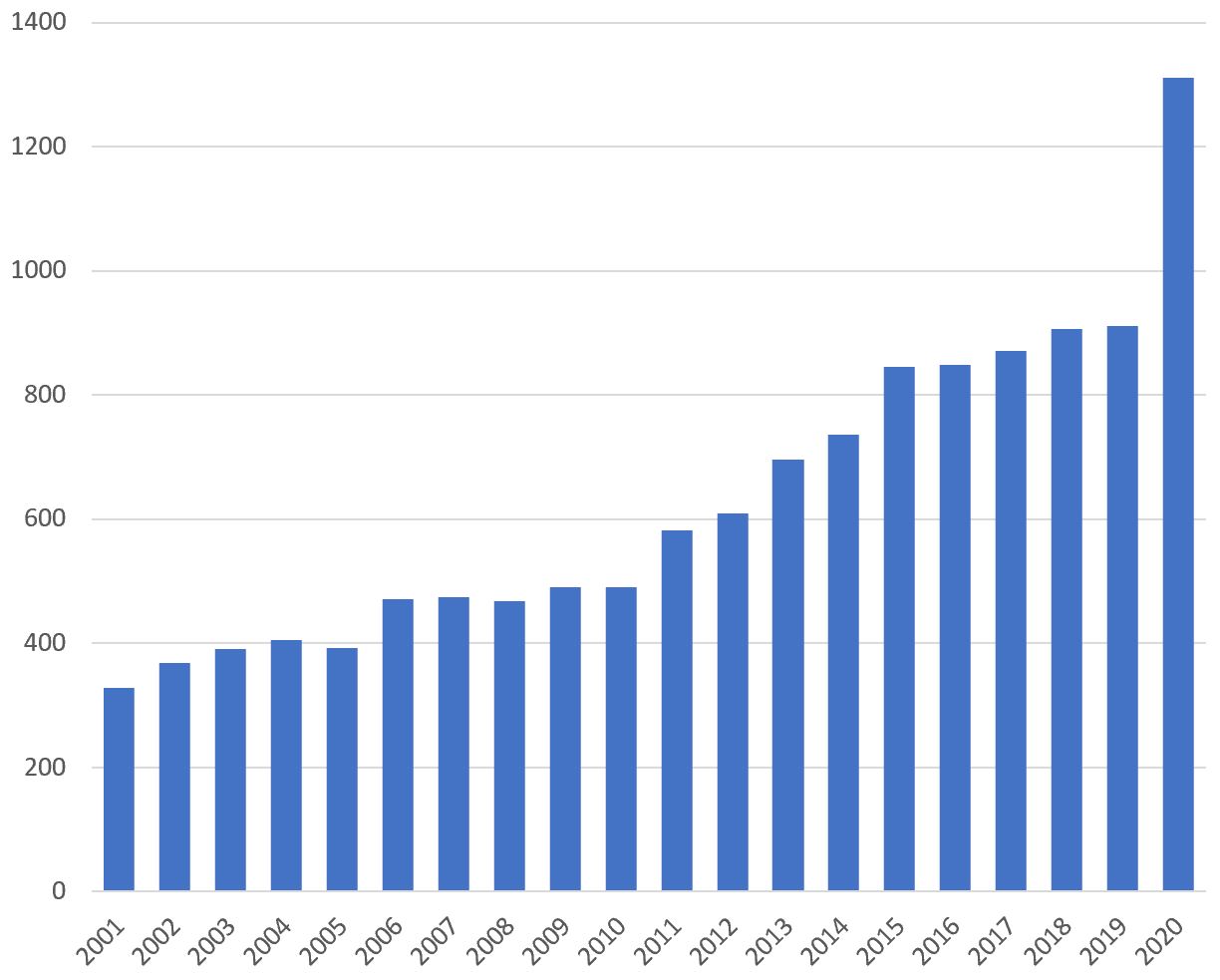
Period Slicer’s main result is to create a new table in the database to perform further analysis. Moreover a simple csv file (tab separated) containing the number of documents for each time-step is also produced – plotting the evolution of documents is then straightforward and can help to define more accurately a satisfying time range (periods containing a few articles, typically less than 100, could lead to too noisy results).
Where to use Custom periods?
Custom periods defined by Period Slicer can then be used in any script involving time periods simply by choosing “Custom periods” as periods parameter.
Choose Orginal Timescale
Choose Orginal Timescale is the option which appears in any script involving time periods (Mapping Networks, terms extractor, periods detector, Epic Epoch), after a custom periods has been defined. In those cases, choose “Custom periods” parameter if needed.

Custom periods can also be used as a variable of analysis on its own: choose Periods as field to draw heterogeneous maps involving time periods as nodes.
 Cortext Manager Documentation
Cortext Manager Documentation