This script is naturally connected to list builder script. It provides users with full control other a set of items that may later get mapped or analyzed. Technically, one or several new field(s) will be created using a key defined by user along previously uploaded TSV (csv) files.
How to use the script
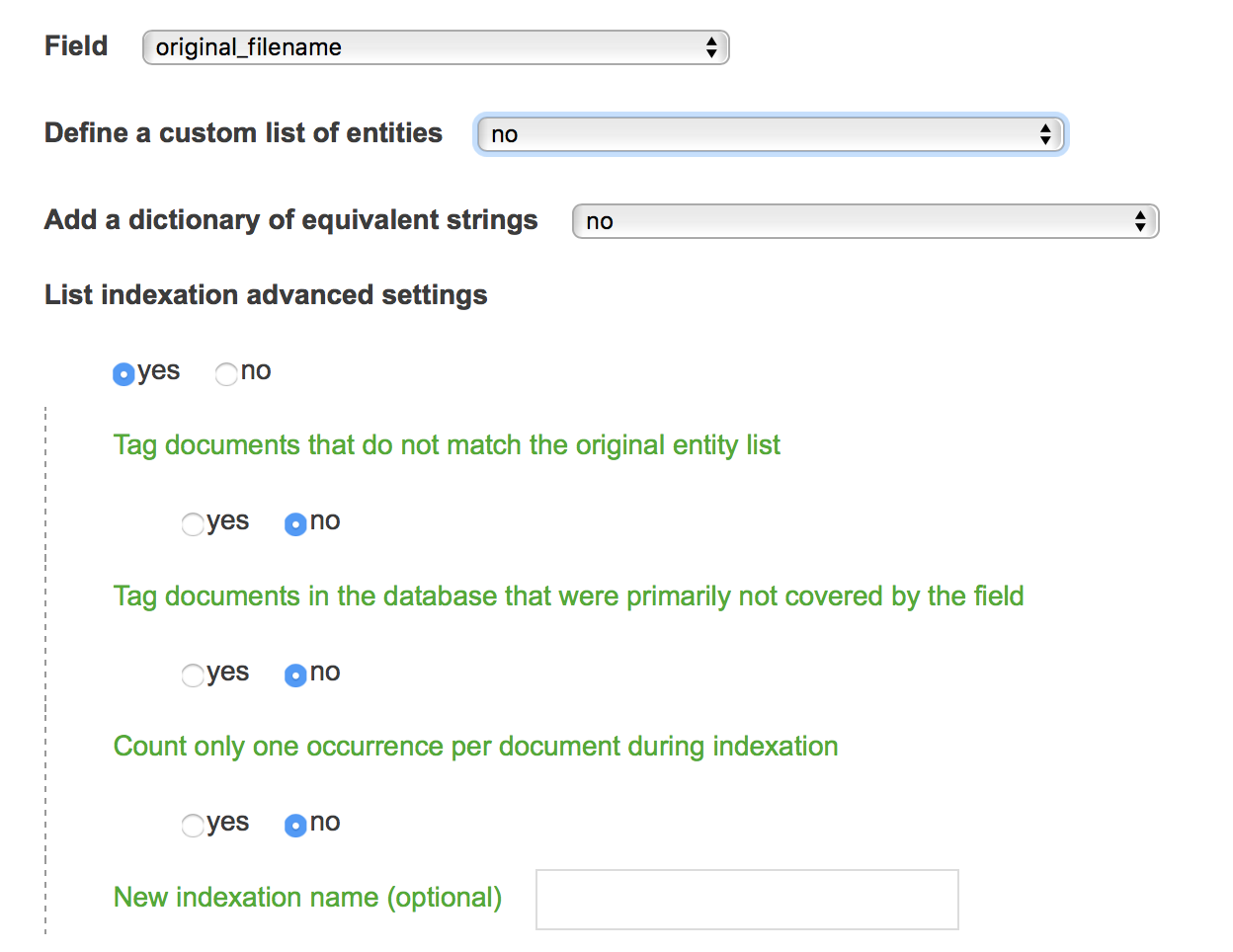
Field
Select the field you wish to work on
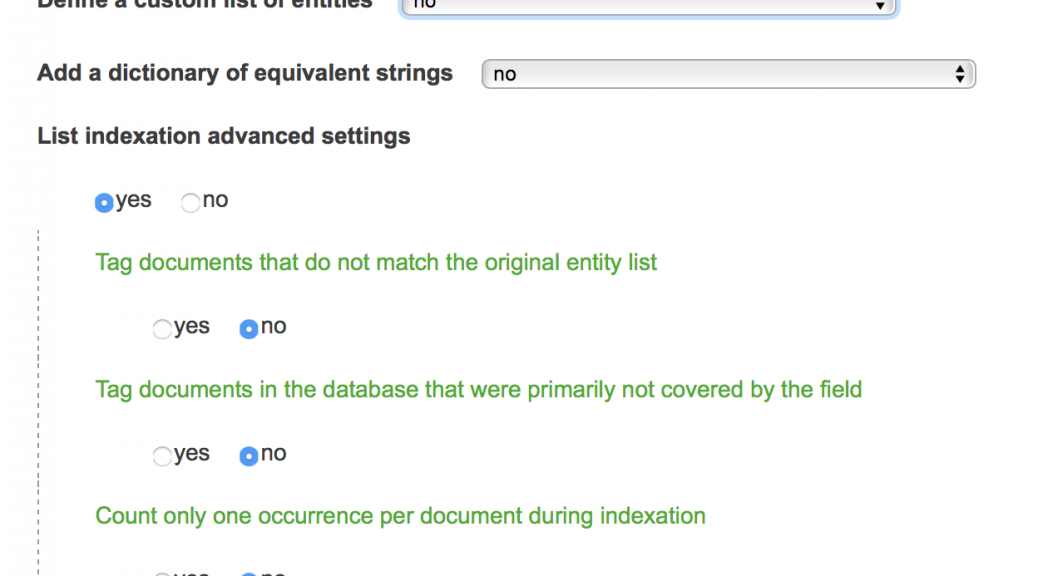
Define a custom list of entities
If checked, user can provide a TSV (csv) file filled with a list of items that will be specifically indexed in the target field (concretely, only the first column of a tabulated TSV file will be considered). By default (unchecked), every entities present under the chosen field will be indexed.
Add a dictionary of equivalent strings
If yes, one should provide a TSV (csv) file made of couples of equivalent strings. Entities from the first column of the TSV file will be automatically transformed into second, third, fourth, (etc.) column entities (remember that the default TSV formatting is tabulation delimited, please use Open Office or Google Sheets if you want to edit it in a spreadsheet software). If an existing entity is not listed in the first column, then it will remain unchanged. Pay attention to the name of your columns as newly indexed variables will be named out of them.
Tag documents that do not match the original entity list
Articles matching none of the proposed entities in the list of entities to consider with be assigned a dedicated tag “null”. Otherwise they will simply be ignored in the new indexation
Tag documents in the database that were primarily not covered by the field
Articles matching none of the proposed categories in the list with be assigned a dedicated tag “null”.
Count only one occurrence per article during indexation
This option is useful when one does not wish that several occurrences of the same entry are mentioned for a given document. For instance, if one wants to compute the distribution of articles published by the USA in a scientific database, it may be useful to reindex the Country field first with this option, such that articles written by at least one american author are counted only once. By default, if several scientists with different US affiliations publish a paper, then this article is indexed with several occurrences of USA in the raw database.
New indexation name (optional)
Finally, one can give a custom name to the newly generated field.
If you are creating or replacing a temporal field (or equivalently tsv/csv column name) you must necessarily named the indexation with “ISIpubdate” .
See the video below for a demo of how to add time step information to a dataset imported from raw text files:
 Cortext Manager Documentation
Cortext Manager Documentation