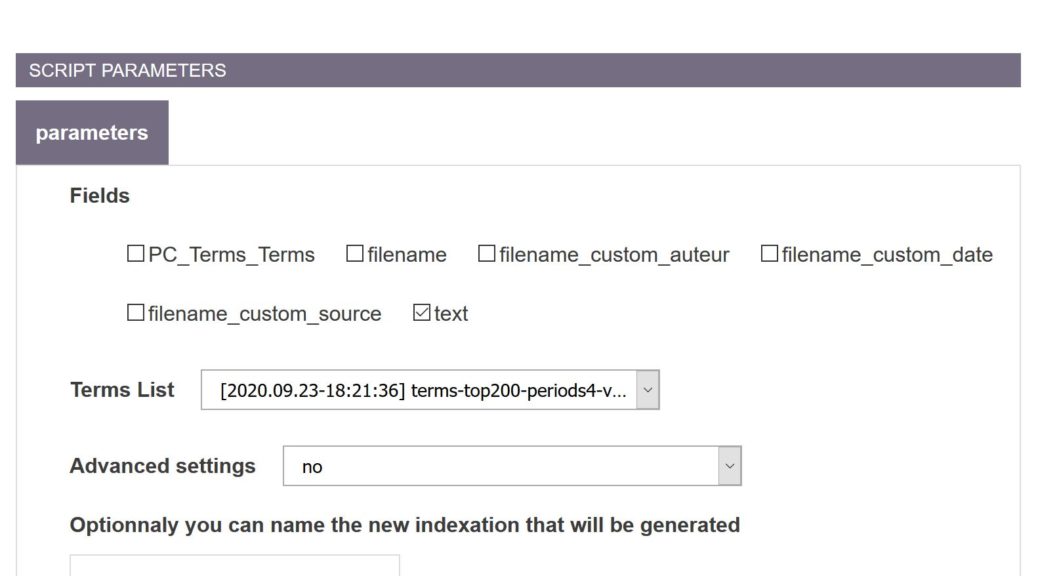
This script works hand in hand with the lexical extraction. Actually, by default, it is even automatically launched every time a lexical extraction is executed. Its basic objective is, given a series of textual fields (provided by the user), to index every term found in a given term list tsv file (specified by the user).
How to use Corpus terms indexer
It then provides more flexibility in the indexation process as users are allowed to edit term list by themselves either by editing their own tsv in a spreadsheet editor like open office (recommended) or Google Spreadsheet or by using the online csv editor provided by CorText Manager.
Only the second and third columns are important for launching an indexation. Concretely, you should provide a tabulation separated UTF-8 encoded file with no text delimiter (which is already the format generated by CorText lexical extraction). The indexer will proceed as follows. The third column (classically entitled “forms”) provide a list (separated by |&|) of strings that will be be indexed using the label provided by the second column (entitled “main form”). It means that each time that one of those strings is found, the database will store this information. The first column is actually secondary. Just be sure to have a different value in each row, or rows with similar information in the first column will be merged under the same entity. Optionally, if your tsv file provides further columns, the rows which ends with a “w” in the last column will be ignored in the indexation. Use the yellow contextual help boxes to tune optional parameters.
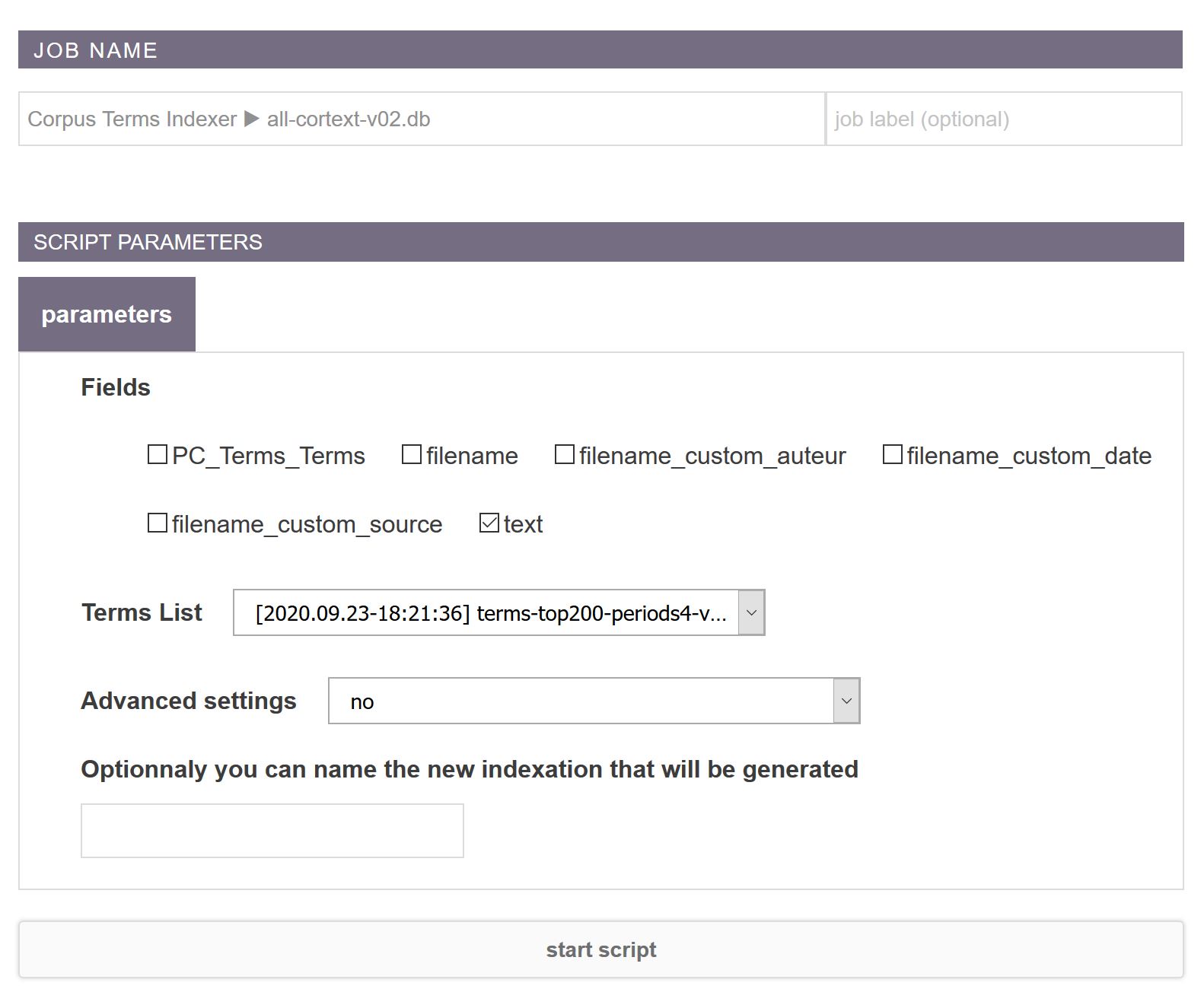
Optionnaly you can name the new indexation that will be generated
The final table will be prefixed with tablename_custom
Advanced settings
Other available options should be straightforward. They include the possibility to check for case when indexing to only index one occurrence of a term per sentence.
Word boundaries
By default, indexation only identifies string separated by spaces or punctuation, you can deactivate this option if you wish to catch all derivations from a string of process a language with no word boundaries.
Case Sensitive Search
Terms search will be performed without checking for the case, choose yes if your preference goes to a case sensitive search
one occurrence per sentence count
Lexical items can at most occur once in each sentence
Use the shared dictionary
A shared dictionary of equivalent terms will be used to enrich the given list of terms. It looks for alternative terms by matching them with some variations due to punctuation (., &…), separators (-…), and accents (ê, é, …).
Tag documents featuring no terms with a “null” label
Entries corresponding to none of the indexed terms with be assigned a dedicated tag “null“. There are several ways to estimate how many documents is covered by the lexical extraction. One of them is to select Yes for this option and run a list builder with all the main forms of the lexical extraction. You will be able to estimate the number of distinct documents which corresponds to the null value regarding the total number of documents. You will be also able to isolate them by querying you corpus (using data = ‘null’).
Ghost Writing Mode
Original content will be copied, with every occurrence of your term list replaced by a token. It may be interesting also to anonymize a list of names, or for confidentiality concerns.
 Cortext Manager Documentation
Cortext Manager Documentation