Contrast Analysis script proposes to show how much two sub-corpus (defined by the user within a dataset) feature a different set of words in its textual content or entities in any categorical field. It uses the excellent library scattertext (Kessler J.S., 2017).
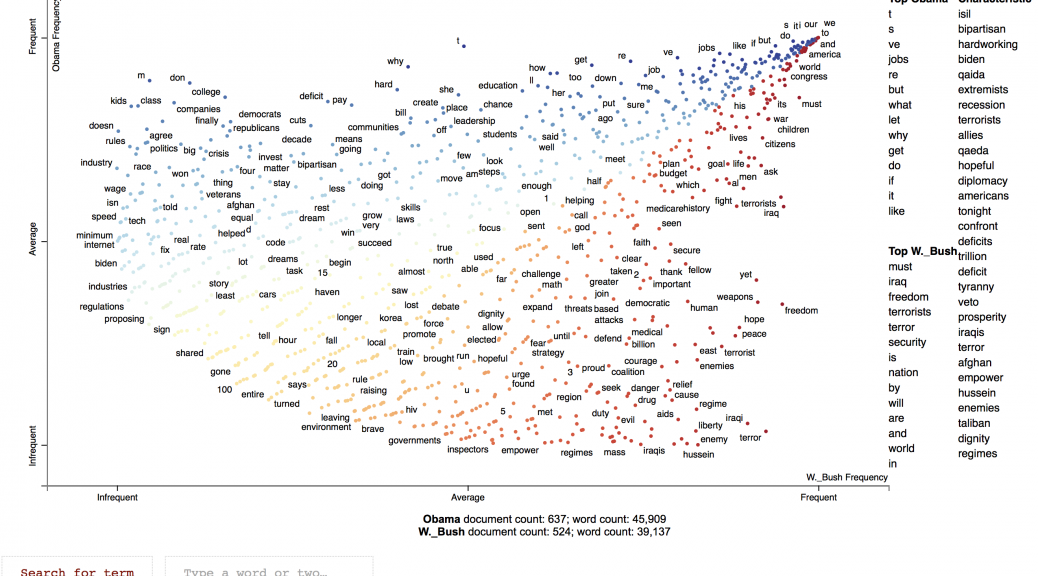
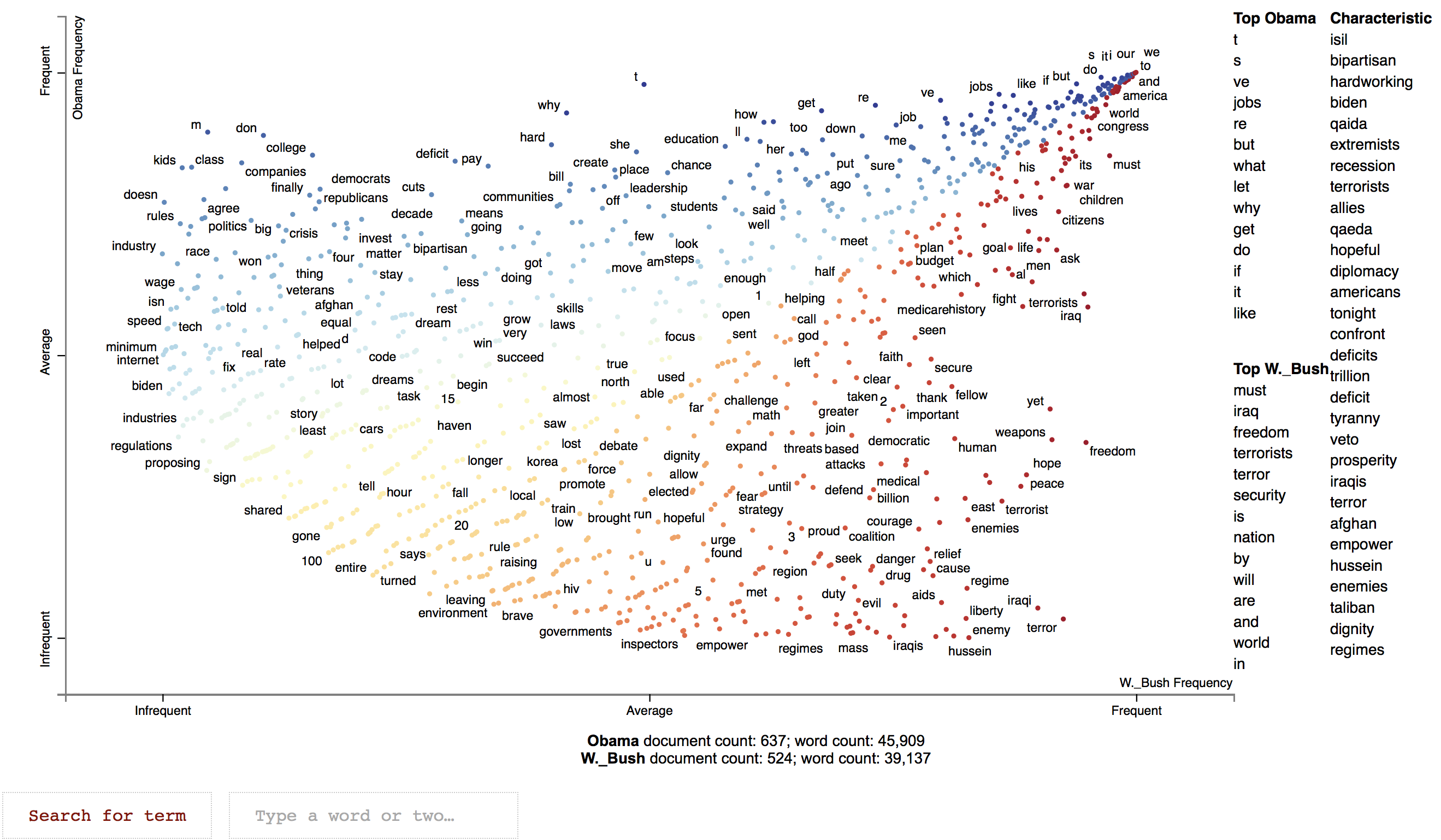
See below an interactive example showing which words were used relatively more often by Obama and Bush Jr during their state of the union adresses.
Contrast Analysis is thought as an exploratory script. As such it is only adapted to compare sub-corpora of small to medium scaled size. Beyond a few thousands of text, the browser may not be able to show the resulting visualization as original snippets from the corpus are also visible.
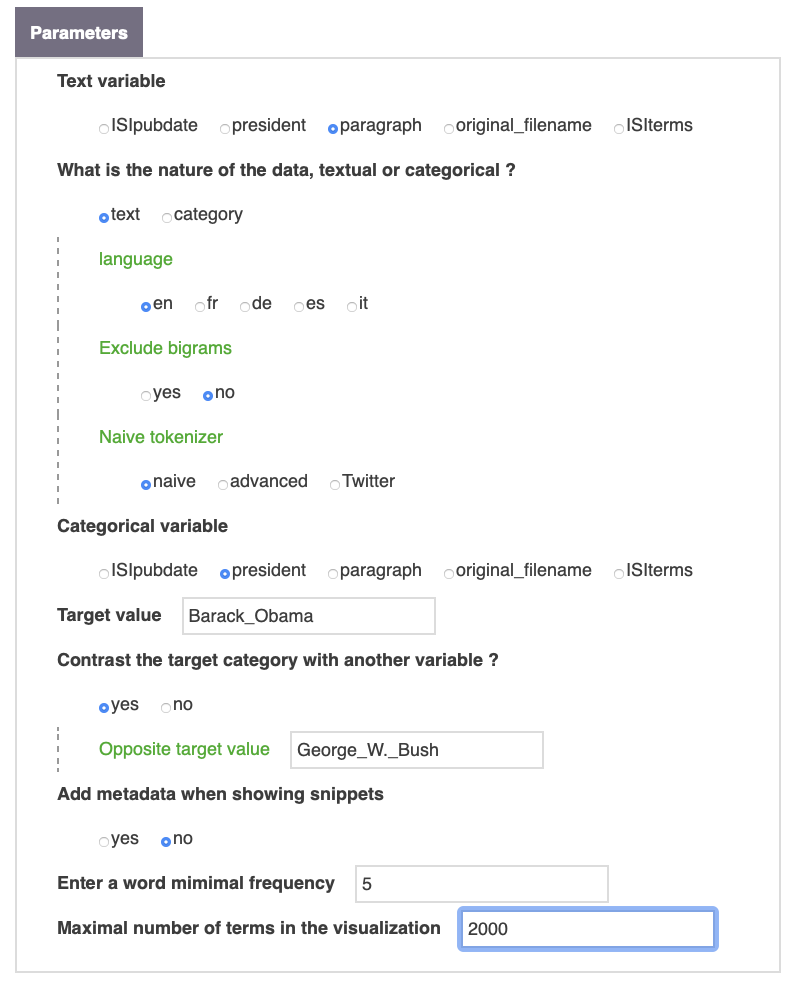
Choose the textual variable
Text variable
Choose the variable to use, which could contains full text or categories.
How to work with it
What is the nature of the data, textual or categorical ?
When selecting a textual field as data category, one has to select a strategy for tokenizing.
text
Choose text if the text variable is full text.
category
Choose category if the text variable contains categories.
Advanced options for textual field (bigrams and tokenizer)
Exclude bigrams
Entities can be bigrams or monograms. The identification of the bigrams is based on the PMI score, for Pointwise Mutual Information, which mesures the likelihood of co-occurrence of two words.
naive
Naive is the default option for the tokenizer. It simply divides the words based on spaces and punctuation.
advanced
For more accurate result, advanced options are also offered to tokenize the sentences (powered by spacy). This option is slower and more resources consuming (avoide it for medium sized corpus).
It’s also possible to use a specific tokenizer for Twitter that also extracts hashtags.
Build the contrast strategy
Categorical variable
It is also mandatory to indicate the category of the variable you want to contrast the composition of. Then type the target value making sure to use the same casing than in the original database (running list builder can be helpful in that respect). For instance in the case of the illustration, paragraph was selected as the text variable. Barack_Obama and George_W._Bush are the two possible modalities of the variable president that are being compared.
Contrast the target category with another variable ?
By default, the target value will be contrasted against the rest of the corpus, but you can also contrast its occurrences with another variable value (e.g. George_W._Bush).
Add metadata when showing snippets
The last set of options will allow you to customize how snippets of texts corresponding to a given term are contextualized with other metadata in the lower part of the visualization.
Enter a word mimimal frequency
Modifying the minimum frequency of terms can also be useful for larger/smaller corpora.
Maximal number of terms in the visualization
One can also limit the total number of terms shown. By default, terms with the largest discriminatory scores are shown.
Reference
Jason S. Kessler. Scattertext: a Browser-Based Tool for Visualizing how Corpora Differ. ACL System Demonstrations. 2017. Link to preprint: arxiv.org/abs/1703.00565
 Cortext Manager Documentation
Cortext Manager Documentation