In digitalized documents, especially those with texts, more than 70% contains geographical information. Nevertheless, a large proportion of this information are not formalized to be projected and manipulated on maps, and there are stored in various forms (Hill, 2006): pictures of places, toponyms in full text documents, addresses, structured metadata or, finally, geographical coordinates. Adding a layer of geographical information in an understandable way for computational treatments is a vast research field (since the 1980s), which has produced different set of methods: Geotagging, Geolocation, Georeferencing, Toponyms detection in full text, and Geocoding.
We are focusing, here, on geocoding. But in Cortext Manager, you are also able to extract toponyms with Name Recognition Entities script (identification of toponyms with GPE), which is a Natural Language Processing method based on language rules, with the use of contextual information to disambiguate toponyms. The two scripts can work one (NRE with toponyms extraction) after the other (Geocoding addresses).
What is Geocoding?
Modern geocoding engines “tackled the problems of assigning valid geographic codes to far more types of locational descriptions [than older methods] such as street intersections, enumeration districts (census delineations), postal codes (zip codes), named geographic features, and even freeform textual descriptions of locations.” (Goldberg et al., 2007)
The CorText geocoding engine has been built to manipulate semi-structured addresses written by humans. So, it is able to solve complex situations as:
- Different formats that rely on national postal services (or data providers), that largely vary across country;
- Non-geographic information (building names, lab names, person names…), that have ambiguities and could be multi-located;
- Ambiguous toponyms (e.g. Is “Paris” one the Paris in Canada or the capital city in France? Is “Osaka” in Japan, the region name or the city name?);
- Alternative and vernacular toponym.
The typical steps needed to move from raw addresses related to documents/objects to coordinates (longitude and latitude) are:
- Normalization: cleaning, parsing (components are more essential than others, like city names or postal code), normalisation (same geographical object with the same name, like abbreviations or ambiguities);
- Matching: comparing the normalized address with one or several reference databases.
Classifying elements contained in an address
First, the tool is doing pre-processing step to do some cleaning and normalisation of the addresses (simplification of the punctuation, aliases and normalising the country names…).
Secondly, to classify elements in the address, the CorText Manager is using LibPostal (Barrentine, 2016): an address parser and normalizer, which is a multilingual, open source, Natural Language Processing based engine, to classify geographical elements in worldwide street addresses. LibPostal has been trained on OpenStreetMap. Libpostal is able to classify objects as: house, building name, near (e.g. “near New York”), level in a building, street number, postal codes, suburb, city, island, state and state district, region, country…
Matching the classified elements with the reference geo-databases
The second tool used by CorText geocoding engine is Pelias, a modular, open-source geocoder built on top of ElasticSearch.
Pelias is comparing the classified elements in an address with a set of large open-source geo-databases (open street map, geonames, open addresses, WhosOnFirst), and manipulates different types of geographic objects (mainly: vectors for streets, points for locations, shapes for administrative boundaries).
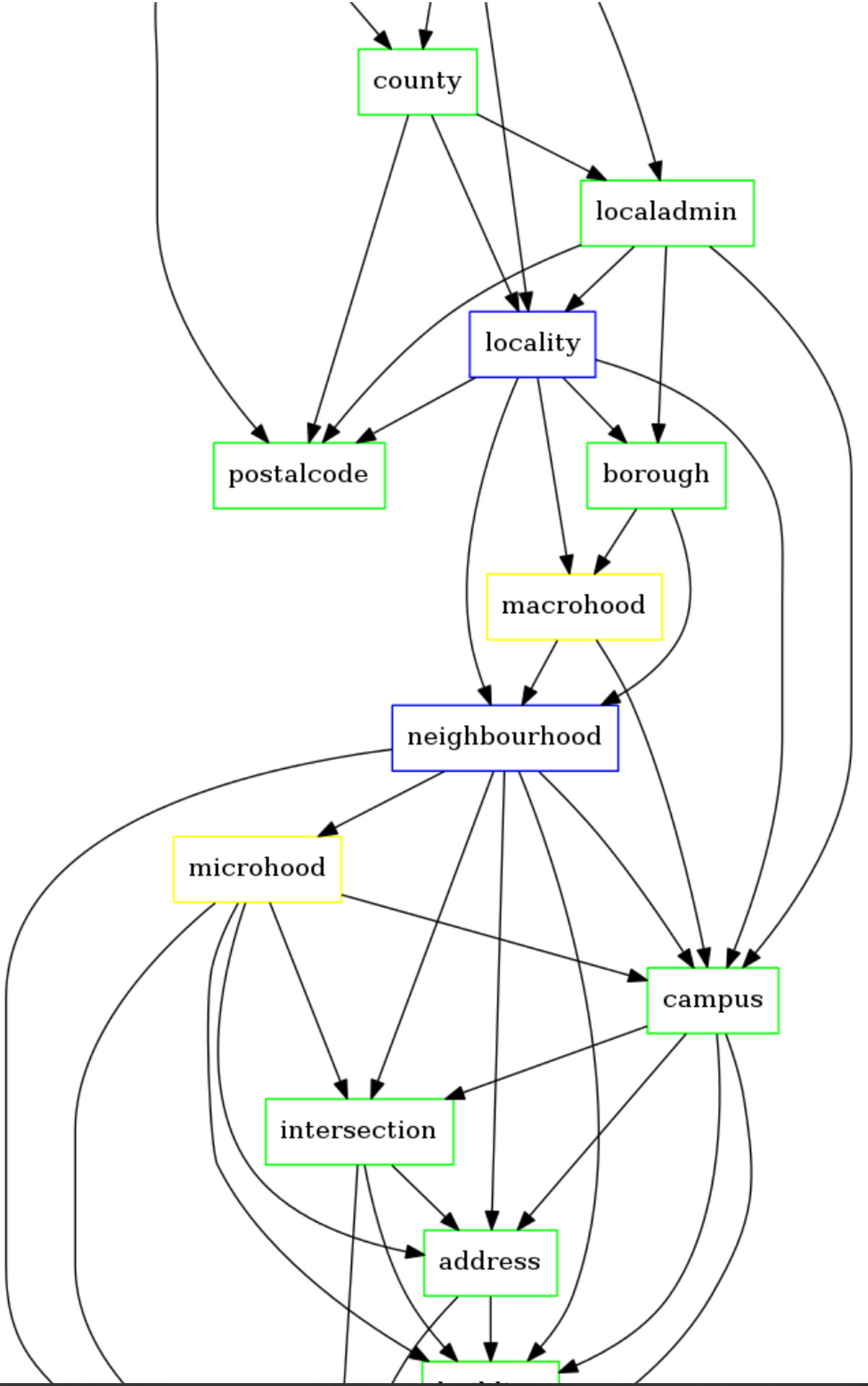
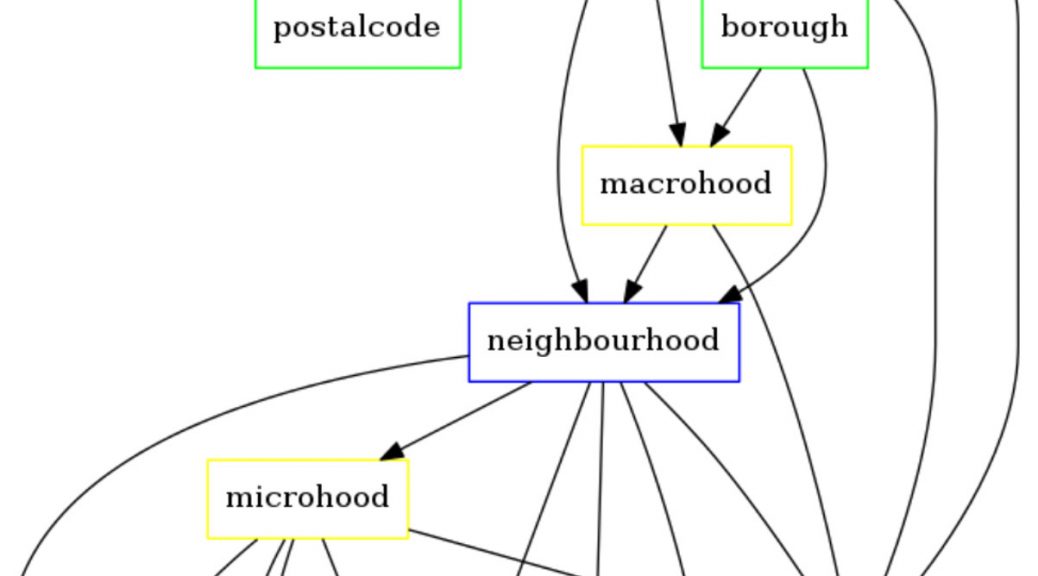
To guess which location (couple of coordinates) is the most probable for a given address, Pelias articulates toponyms classes both vertically (administrative boundaries, mainly hierarchical nesting) and horizontally for context dependant toponyms (within a country, or for a given language: such as vernacular names, campus names, borough in a city, direction… when having different names for the same original geographical object). This requires a large graph with connected classes. They are detailed in WhosOnFirst’s ontology, which has been designed to understand “Where things are (and what they mean)”.
For the remaining ambiguities (e.g. when having “Paris” without any other information), the geocoding engine is using external variables (popularity criterium, such as number of inhabitants) to decide which candidate is the best (e.g. and to choose “Paris, France” instead “Paris, Texas, USA”).
Methods accessible through CorText Geocoding service
We are promoting this two steps approach (classification step and comparison step), with four options to fit the needs of the researches conducted by our users: from meso scales (e.g. regional level) to smaller geographical spaces (e.g. building names, streets or neighbourhoods).
As detailed below, the address field should contain at least a country name. Ideally, country names should follow ISO standard, even if CorText geocoding service works also with a set of country name aliases. The country name is used as a pivot to filter candidates, and improves drastically the quality of results.
Meso geocoding
Filtering organisation names
Organisation names, street names, person names and postal boxes are removed in order to reduce ambiguity (e.g. for multi-located compagnies or laboratories), and to retrieved more aggregated geographical information. Addresses can be located from the postal codes scale (sub-city scale) to urban areas and metropoles (sub regional scale, as for county). This method is opportunistic as it takes less ambiguous information first (postal codes), to end with more ambiguous (city names, and finally building and street names). Depending of the tagged elements in the address, the geocoding engine will decide which candidate and scale are the best. This method is made to cover a large variety of situations with a good quality of the results.
Priority on city scale
Tagged addresses will be searched in the specific sub-area (meso area as regions or counties) and retrieved coordinates as frequently as possible at the city scale. It tends to reduce the variety of geographical objects retrieved and to narrow the scales of the results on centroid coordinates of cities. This method is useful to build analysis at the city or regional scale.
These two approaches produce aggregated coordinates (shapes located by a centroid), with a less spread spatial distribution.

Full addresses geocoding
Priority on street scale
tagged addresses will be searched in the specific sub-area and retrieved with a very fine-grained toponyms or building names (and POI) detection. Street names, building names are prioritized. It needs a well and uniform full addresses coverage (with street names and/or building names) and fits when follow precise intra-urban local spatial dynamics. It tends to produce a spread spatial distribution of the coordinates.

No customisation
Full addresses are sent without any customisation (no pre-processing step, no toponym filter, no prioritisation of the scale) to the geocoding engine and let it decide which geographical object is the best.
Parameters
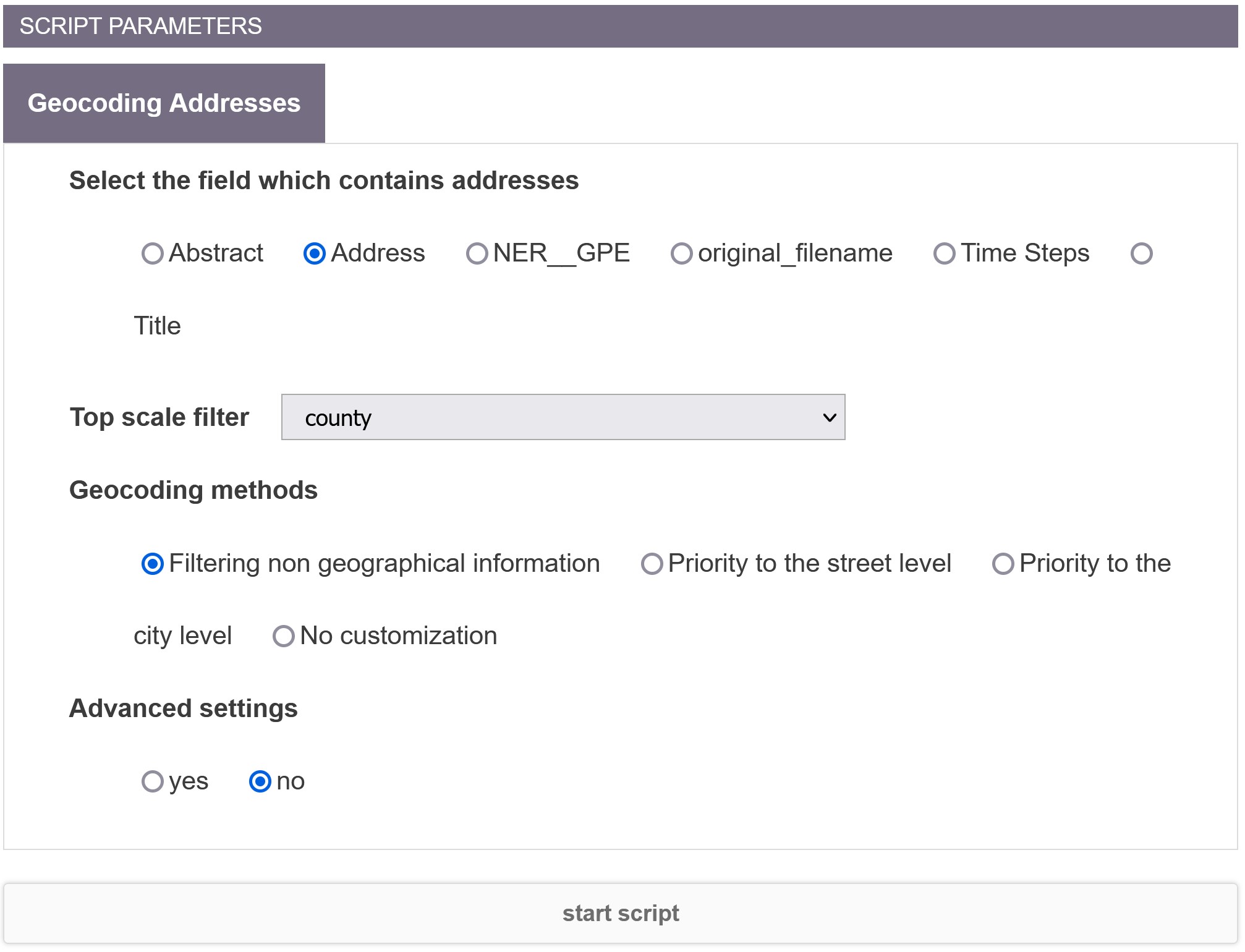
Select the field
Select the field which contains the list of address. It should be formatted a least with a city name and a country name (e.g. “Paris, France”). Ideally, country names should follow ISO standard. As the country boundaries are an important information to locate addresses, CorText Geocoding service is able to deal with aliases for country names (e.g. USA, US, United States of America). When needed, intermediary names (state, region, county….) are also useful to help reducing ambiguities. Postal codes (but not postal boxes) are powerful and non-ambiguous information and are supported for 11 countries: Austria, Australia, Canada, Switzerland, Finland, France, Great Britain, Japan, Liechtenstein, Netherlands, United States of America. For a higher accuracy, please consider removing postal codes for countries which are not listed.
Top scale filter
Addresses won’t be geocoded above this scale. If having centroids at the “region” scale is not an option, “county” will provide a better precision. For an address geocoded at county or city scales (or even below), all the adminsitrative hierarchy is calculate based on the founded coordinates (including city, region and country names) and added to the final results.
Geocoding methods
Choose which geocoding method to use according to your needs. See the above definitions. “Filtering organisation names” is recommended as it will provide the best ratio between the quality of the results and the coverage. As geocoding addresses is slow, “Filtering organisation names” is also the fastest option (e.g. 4 days for around 2 millions of addresses). To expand the coverage you could consider to choose 0,4 as a “Confidence threshold“. It will also increase the proportion of false negatives.
New added variables
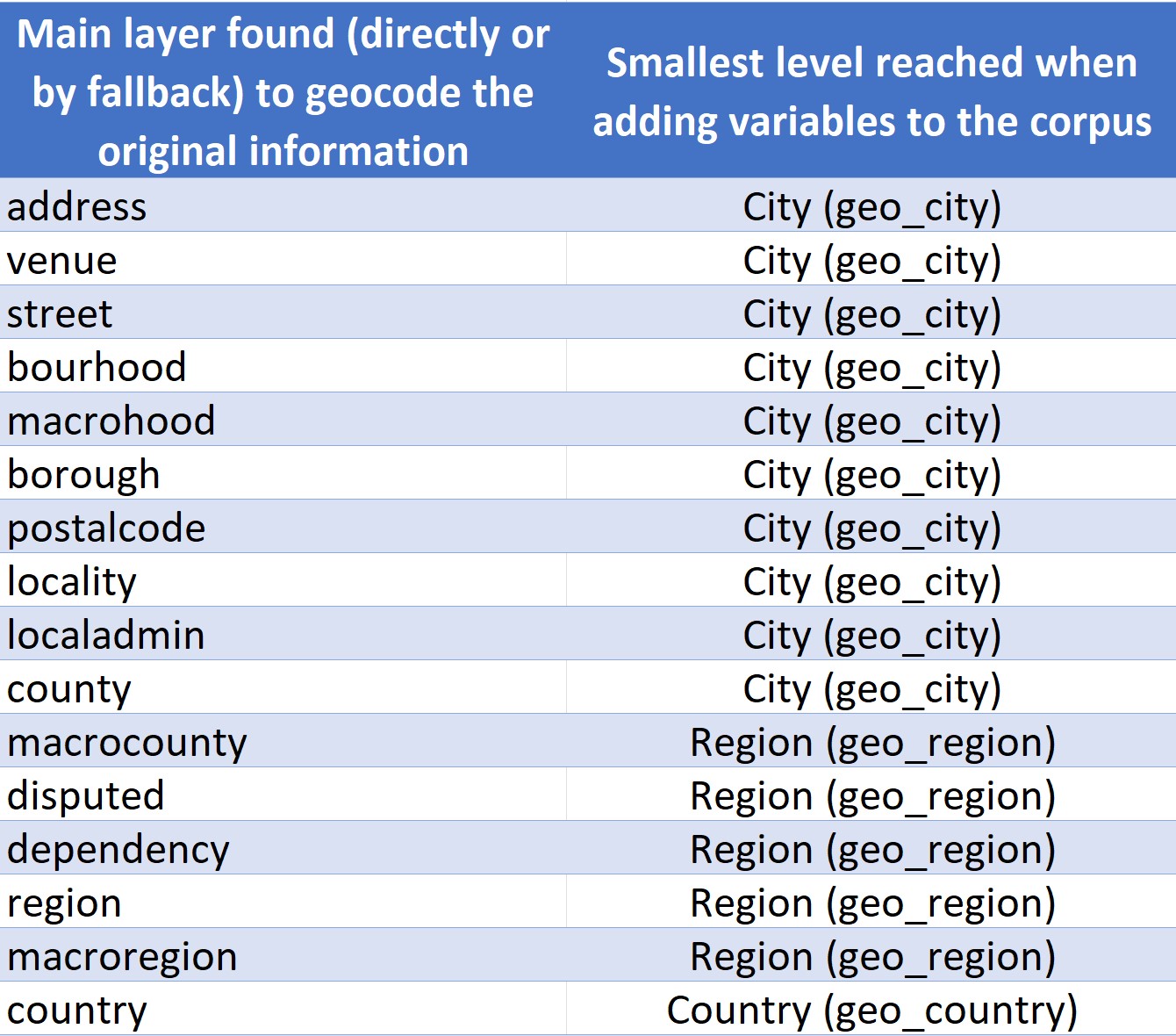
Depending the method chosen, users will get different results. The Cortext Geocoding engine is not only able to geocode your addresses (longitude and latitude coordinates), but also enrich your corpus with three new variables that can be used in other CorText scripts:
- geo_city: name of the “city”, chosen between locality name, localadmin name, neighbourhood and county name. More generally geo_city is the locality name, rather than the official administrative name of a city;
- geo_region: region name identified by the hierarchy or identified directly in the address if it was the only information associated with the country name. Regional layer is feed with different geographic elements that rely on the administrative divisions of the country (e.g. state in US, department in France, prefecture in Japan);
- geo_country: standardised country name (ISO standard).
Depending on the lowest layer found (directly or by fallback) during the geocoding process, the completeness of the variables added to the dataset may vary. See below how geo_city, geo_region, geo_country are built according to the layer.
Geocode place names (e.g., from NER script)
When toponyms come from Named Entity Recognizer script an extra step is added before geocoding the extracted toponyms: checking if the ids are unique. Since the NER, Term Extraction and Corpus Term Indexer scripts, are designed to extract terms and build co-occurrences from texts, they store a distance value (e.g., to exclude links between terms when they are too far in the original texts) where ids may not be unique when these terms are close to each other. The geocoding process need a unique link between toponyms and documents. So, a new variable is created which is a copy of the original variable:
- From the NER script: geo__NER__GPE is created for GPE entity type
- More generally: a variable with the structure of geo__name_of_the_original_variable is added to the dataset
This new variable is used to store the list of toponyms which could be refined through GeoEdit tool.
Example of application
This example uses a 3D printing dataset with all scientific publications published in a given time period.
- Geocoding of all addresses from documents (addresses of authors), with “Filtering organisation names” method;
- Refine the results using GeoEdit tool;
- Lexical extraction of textual information (top 150 keywords, without monograms);
- Clustering of extracted terms with distributional algorithm (Terms – Terms, with Top 100 keywords);
- Clustering of geocoded cities (geo_city – geo_city, top 100, raw, Top 3 neighbours), with a 3rd variable to tag clusters (the name of the semantic clusters: PC_Terms_Terms and chi2 measure to tag clusters) with the top 2 labels for the tagging variable (Number of labels to show for each cluster);
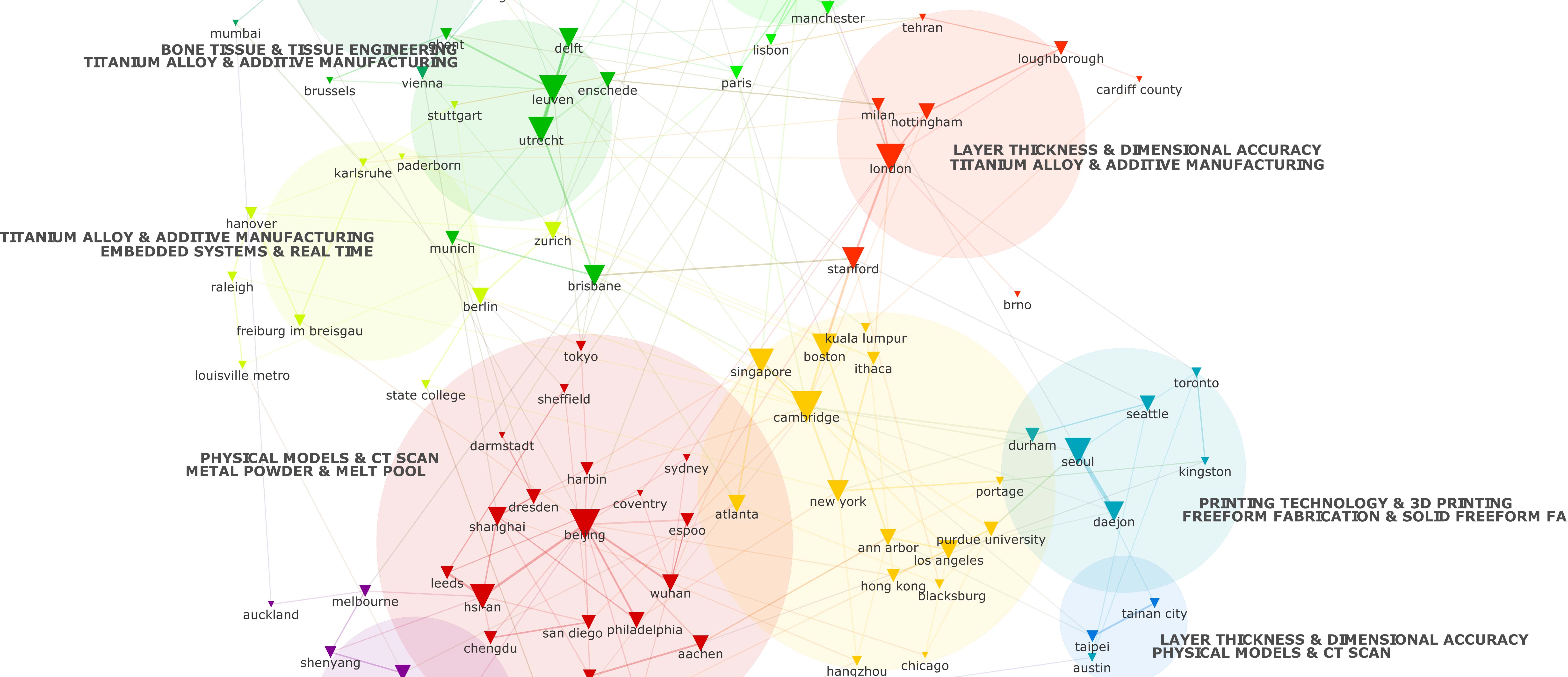
In the map “purdue university” is a location in US where the university is located next to the city of Lafayette in the state of Louisiana (around 2 kilometres from the 127,657 inhabitant city, according 2015 U.S. Census estimates). In CorText Geocoding Service, this location is considered as an independent geographical object (with its own postal code, where administrative boundary of the university does no overlap the boundary of the city of Lafayette). The other locations mentioned onto the map are city names, even if the coordinates of the locations found (longitude and latitude) are under the scale of these cities.
With the top 2 semantic clusters labels written next to the clusters, it is possible to estimate the thematic specialisation of geographic communities built on the top of authors collaborations in the 3D printing scientific field.
- Run the GeoSpatial exploration tool to map geocoded addresses accross Urban and Rural Areas (URA).
Improvements and issues
Solved issues
- Brussels, Belgium (solved janv. 2020) Previous Geometry: bbox: [4.40587107174,50.7251287505,4.46765791089,50.7512263859] latitude: 50.733183 longitude: 4.436117 -> New Geometry: bbox:[4.244673,50.763691,4.482281,50.913716] latitude: 50.836055 longitude: 4.370654
- Sao Paulo, Brazil (solved feb. 2020) Previous Geometry: bbox: [-47.5090274788,-1.32548087815,-47.5005411811,-1.32080095562] latitude: -1.32311 longitude: -47.504873 -> New Geometry: bbox: [-46.826199,-24.008431,-46.365084,-23.356293] latitude: -23.570533 longitude: -46.663713 Population has been updated to the last value 12,176,866 inhabitants
Known issues
- Longitude and Latitude with 0 values: when using Filtering organisation names for a very few proportion of addresses (less than 0,002% in our tests), longitude and latitude received a 0 when addresses have been geocoded with a postal codes (layer = postalcode). This appears when all the previous steps failed. This information is kept as CorText Geocoding Service has found for these addresses the city and the region names.
- Addresses in Puerto Rico are not geocoded: when having a full address in Puerto Rico (e.g. “CONCORDIA #62 ESQ AURORA, 731, PONCE, PR, USA”) CorText Geocoding Service fail to geolocate the address. You may want to shorten these addresses by removing street names and country name (and look only for “PONCE, Puerto Rico”) or to use geo-refine tool. This case may occure also for some other dependencies.
Section to expand with your comments.
References
- Barrentine, A. (2016). Statistical NLP on OpenStreetMap: Toward a machine-interpretable understanding of place. Medium – Marchine Learnings. Retrieved from https://machinelearnings.co/statistical-nlp-on-openstreetmap-b9d573e6cc86
Refer to this work
This set of methods have been funded by the European Union under Seventh Framework Programme RISIS.
If you have found the tool useful, we would be grateful is you would refer to this work by citing it in your own documents or publications:
Villard, Lionel & Ospina, Juan Pablo (2018). CorText Geocoding service, ESIEE Paris, Paris-Est University. https://docs.cortext.net/geocoding-addresses/
 Cortext Manager Documentation
Cortext Manager Documentation