Welcome to the documentation of Cortext Manager, the data analysis platform for citizens and researchers in the social sciences and humanities.
Throughout these pages we will often refer to a corpus. By that we mean information on an ensemble of documents, containing for each document both its textual contents and its metadata. Metadata will vary from corpus to corpus, but usually contains information on the authors, dates, editors or locations pertaining to the document.
Begin your project and analyse your corpus
All the action in Cortext Manager takes place within a project, and so you must start by creating one. Projects help you organize your work. Various options are available in the dashboard of CorText Manager to allow you to manage your projects and the analyses they contain. Your projects can be shared with collaborator(s). They can be archived, fully downloaded into one zip archive and deleted. See “Manage projects” section for more details.
The first step to treat your corpus is to produce and upload it. You should then be led to parse it (the parsing script should be automatically launched after upload). This task will convert the original corpus into a format (an sqlite database) that other tasks in Cortext Manager are prepared to use.
Once you have completed the data parsing step, different tools – we call them “scripts” or “Cortext methods” – are at your disposal to analyze your corpus. It all beings with choosing to start script.

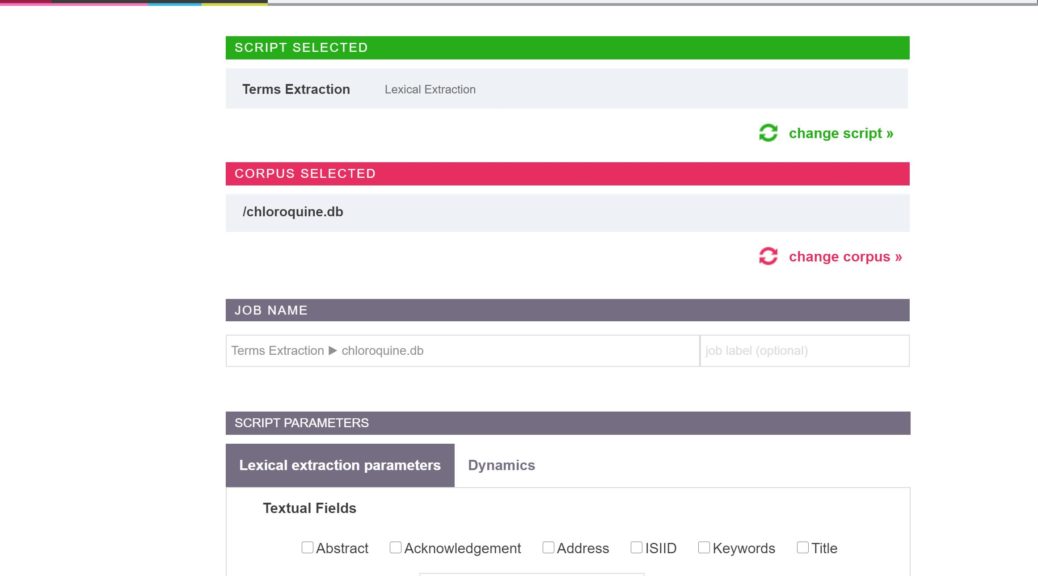
When starting a script, you will be asked to choose which script to start, and then a corpus to apply it to. The corpus should be one of the parsed databases (.db file) in your project. Then, a form in which to provide the parameters for the analysis will appear. Some parameters are required, while others have default values. After choosing the parameters, you may optionally label the analysis, and proceed to start the script.
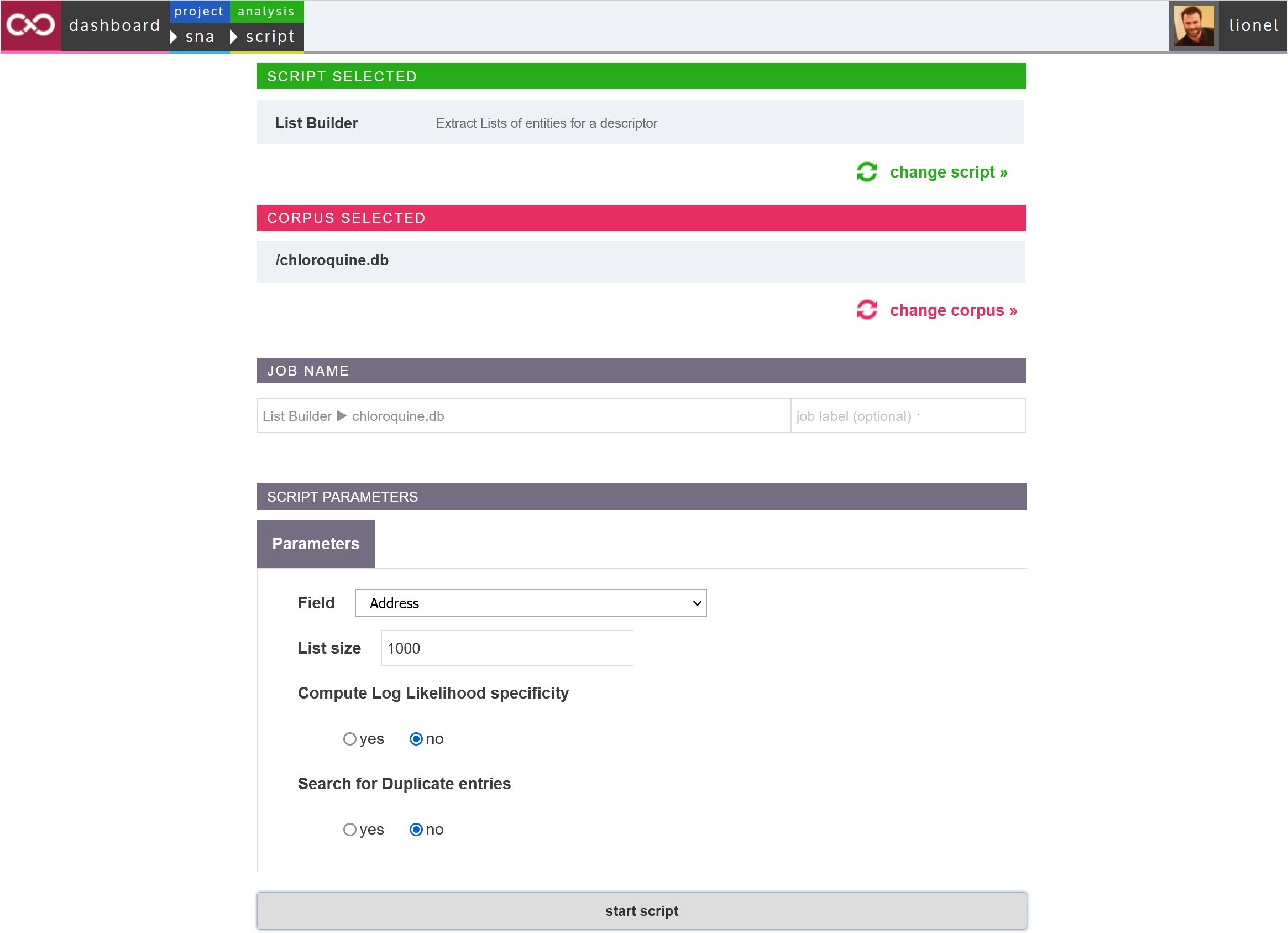
Start script form: select the script you wish to launch, then the corpus (.db file)

Once a script is started, an entry for the new analysis will appear in the project page. Once it completes, the outputs are presented there. The color of the flag at the top of the analysis’ entry indicates whether the script reach completion (green flag) or not (red flag). At the bottom of each entry, five icons allow you to perform different actions on the analysis (relaunch, log, delete, tag as ‘favorite’ and comment). See the “Manage projects” section for more details.
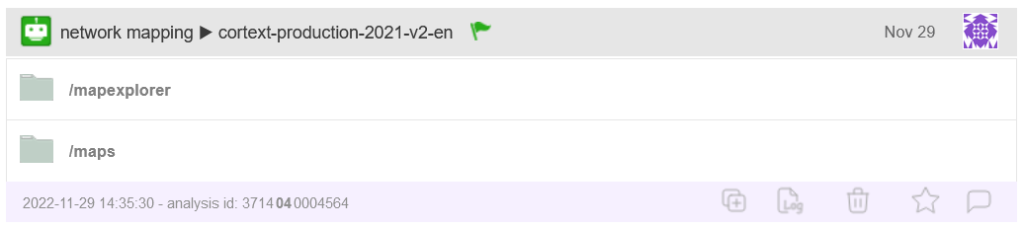 Entry created in the project dashboard after launching a script
Entry created in the project dashboard after launching a script
CorText Manager galaxy
Cortext Manager proposes a full ecosystem of modeling and exploratory tools for analyzing text corpora.
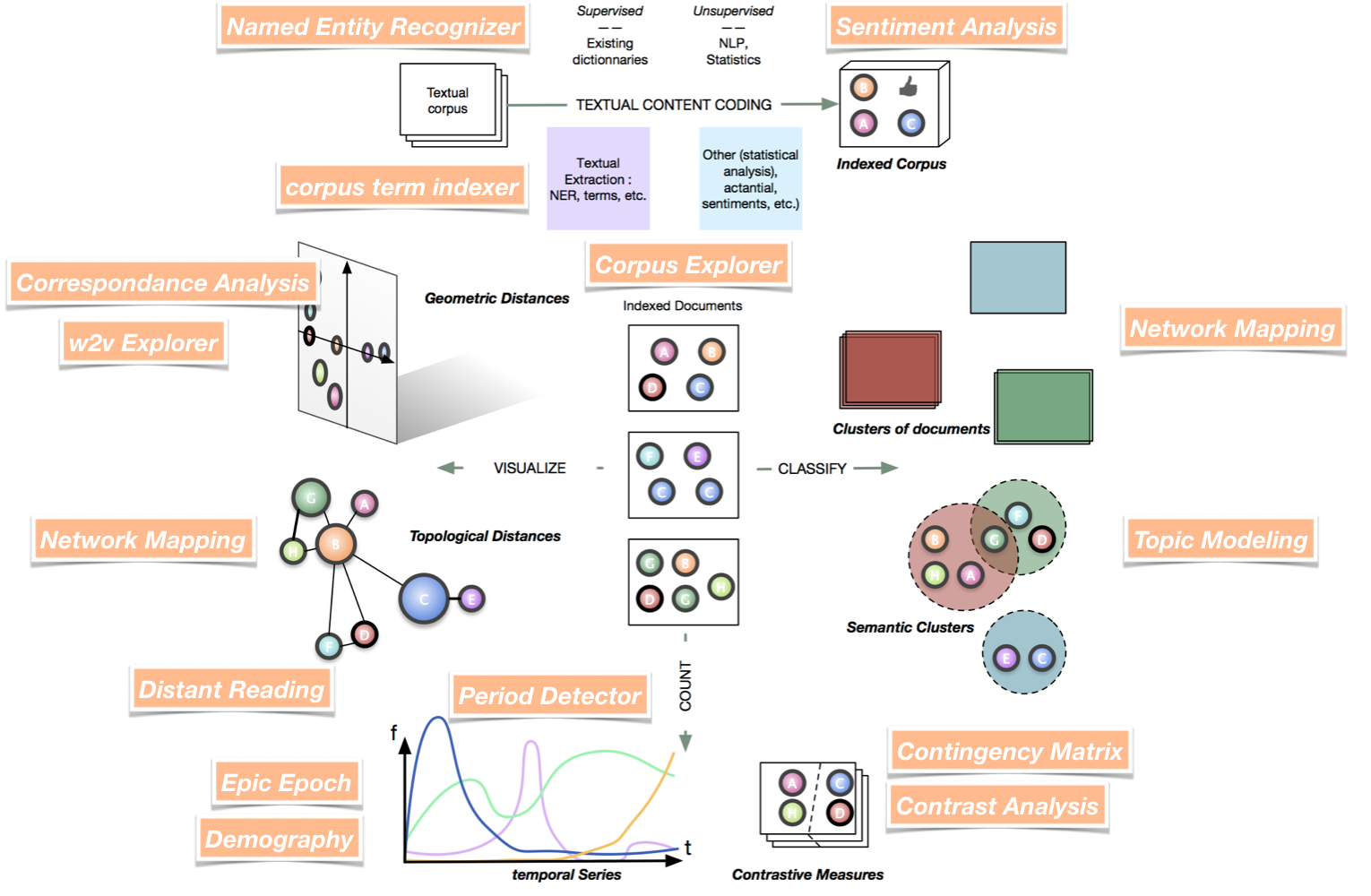
A global schema with most methods provided by Cortext Manager
Some scripts work one after the other (e.g. terms extraction and terms indexer), while some others could be run at any time (e.g. demography).
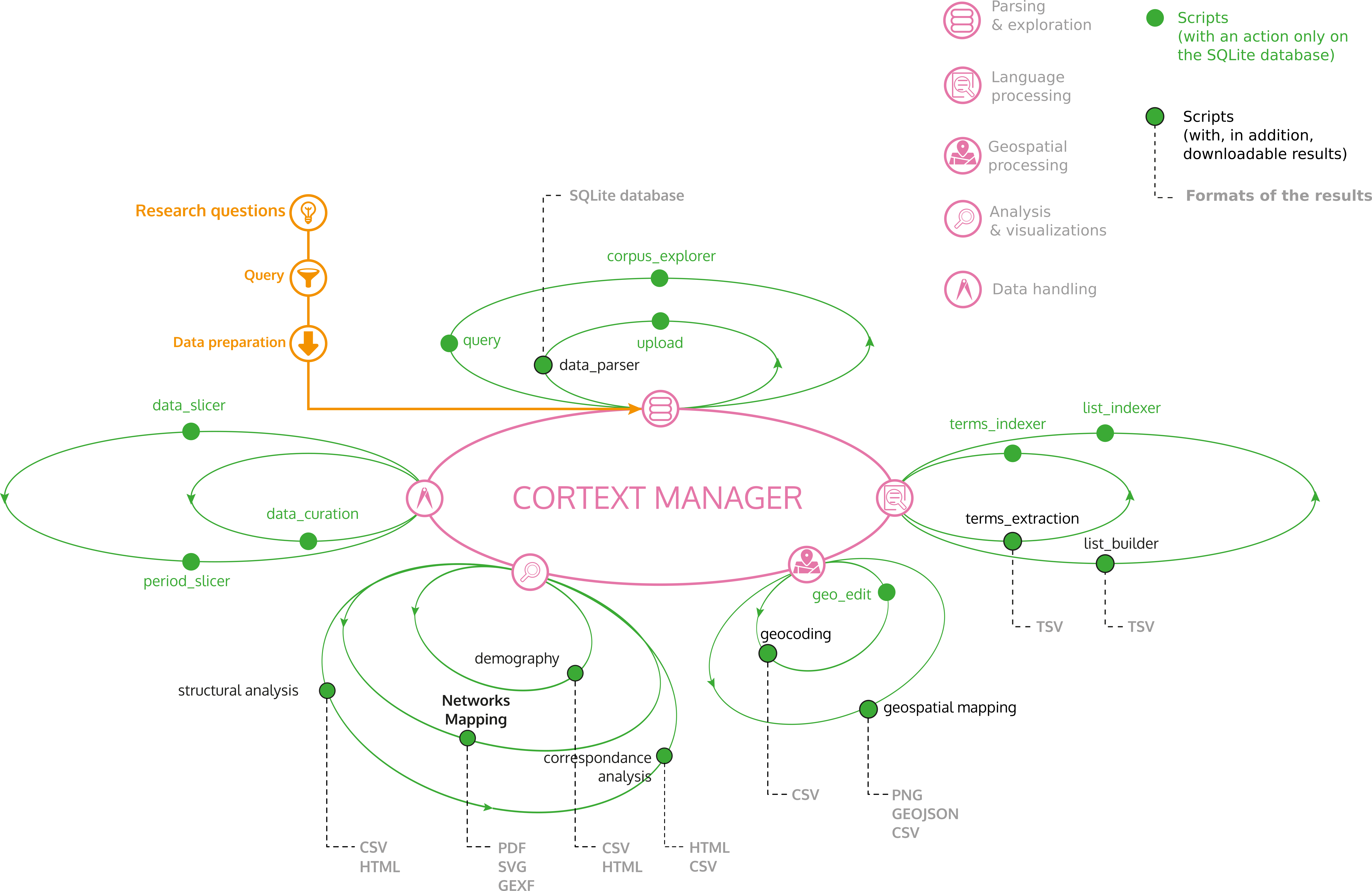
As a user, you are free to define your own workflow of analysis, as illustrated above for a selection of methods. The main menu of this documentation provides the list of available methods and tools.
Prepare the corpus for later analysis
The so called processing scripts are typically used to prepare the corpus for later analysis, when needed. They allow you to extract, transform and match information, such as to find the names of cities and convert those to coordinates, or search the text for names in a list you provide and index your documents with them. They can be categorized into Data Processing, Text Processing, Time Processing and Spatial Processing.
- Lexical Extraction automatically extracts list of pertinent terms using NLP technics
- Named Entity Recognizer detects named entities such as persons, organizations, locations, etc
- One can also indexes databases with their own custom terms list, a dedicated interface is proposed to easily create your own lists
- Period Detector longitudinally analyzes the composition of your data to automatically detect structurally distinct periods
- You can customize the periods you wish to work on with Period Slicer
- Quantative data may also be very easily pre-processed with the Data Slicer script
- Query A Corpus to create any sub-corpus resulting from a complex query
- Different scripts allow to filter out and clean categorical lists: List Builder and Corpus List Indexer
- Distant Reading builds an interface which allows to compare the dynamic profiles of words in a dynamic corpus
- Geocode addresses and add to your corpus city names, region names, longitude and latitude coordinates;
- Geospatial exploration tool to explore the geographical distribution of longitude and latitude coordinates across Urban and Rural Areas, NUTS and other spatial units.
Observe your corpus
An additional category for Data Exploration collects scripts that let you directly observe your corpus.
- Demography will generate basic descriptive statistics about the structure and evolution of the main fields in your dataset
- Distant Reading builds an interface which allows to compare the dynamic profiles of words in a dynamic corpus
- Contrast Analysis is an exploratory tool allowing to visualize terms with are over/under-represented in a given sub-corpus
- Word2Vec Explorer maps large number of words which positon has been trained using word2vec model
Advanced data analysis methods
And finally, you’ll find the more advanced Data Analysis methods:
- Heterogeneous Networks Mapping performs homogeneous or heterogeneous network analysis and produces intelligible and tunable representation of dynamics
- SASHIMI combines robust statistical modeling and interactive maps to provide a hierarchical navigation of the full corpus and of the relationships between terms, documents, and metadata.
- Topic Modeling offer a solution for analyzing the semantic structure of collections of texts
- Contingency Matrix provide a direct visualization of existing correlations between distinct fields in your data
- Correspondance Analysis script provide minimal facilities to perform a multiple correspondance analysis on any set of variables
Now that you’re familiarized with the general aspects of Cortext Manager, we hope you’ll go ahead and try it out.
Datasets readily available and CorText Manager forum
Don’t hesitate to ask for advice on the forum. You’ll just be asked to register there, as currently you can’t simply use your Cortext Manager credentials. You may also like to watch our videos, for a guided tour, or visit the gallery page to discover some interesting uses of Cortext Manager.
If you want to play around but can’t think of any dataset readily available, feel free to use this dataset of recipes from a old Kaggle competition. It features a set of almost 40,000 cooking recipes, along with their regional cuisine of origin as metadata. Upload the zip file, parse the corpus by declaring a json file in the parameters, and start exploring.
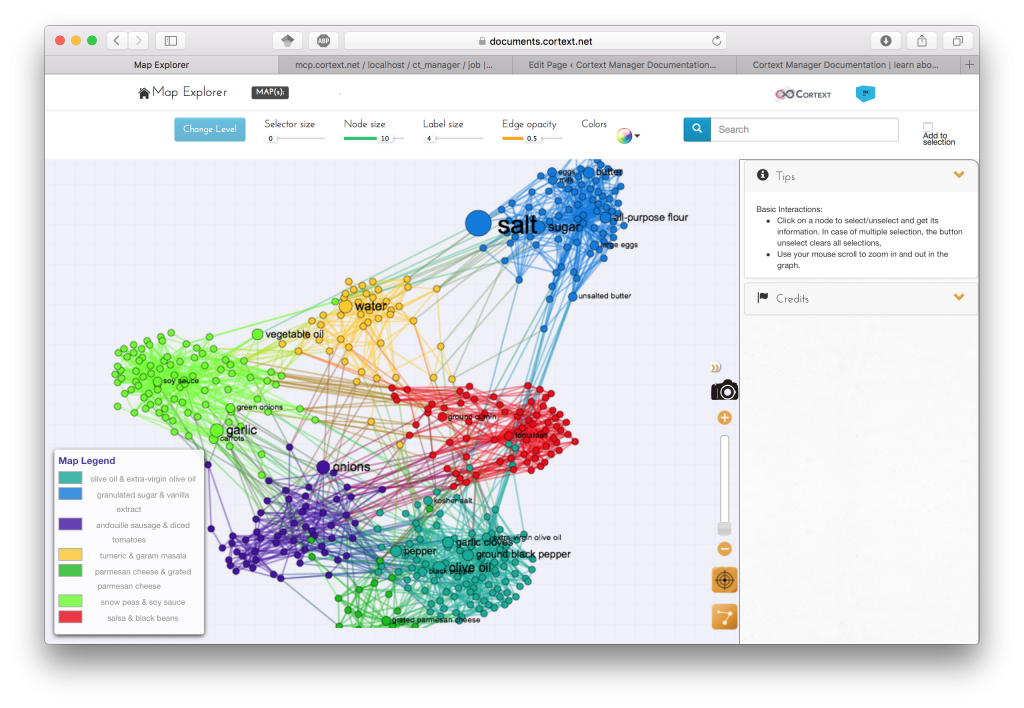
You may also want to try this corpus compiling every State of the Union address since 1790, with discourses divided in paragraphs, and the speaker and year of address included as metadata.
The two latest training materials
An additional deck of documents is found in our training materials section. In addition to this website, we regularly organize workshops and some material is available in this repository.

[English] Introduction to text analysis using Cortext by Olha Nahorna
[French] Présentation pour l’Association des Diplômés de l’École de Bibliothécaires
Works published with CorText Manager
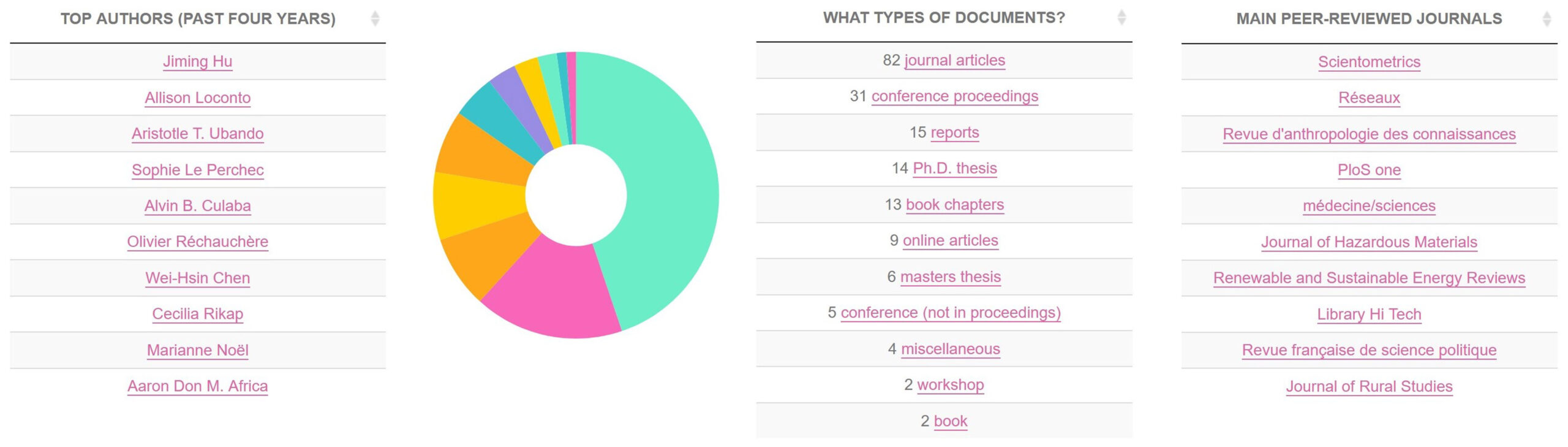
Have a look to what users have published using CorText Manager and appreciate the variety of topics, contexts and uses cases.
Latest documented scripts
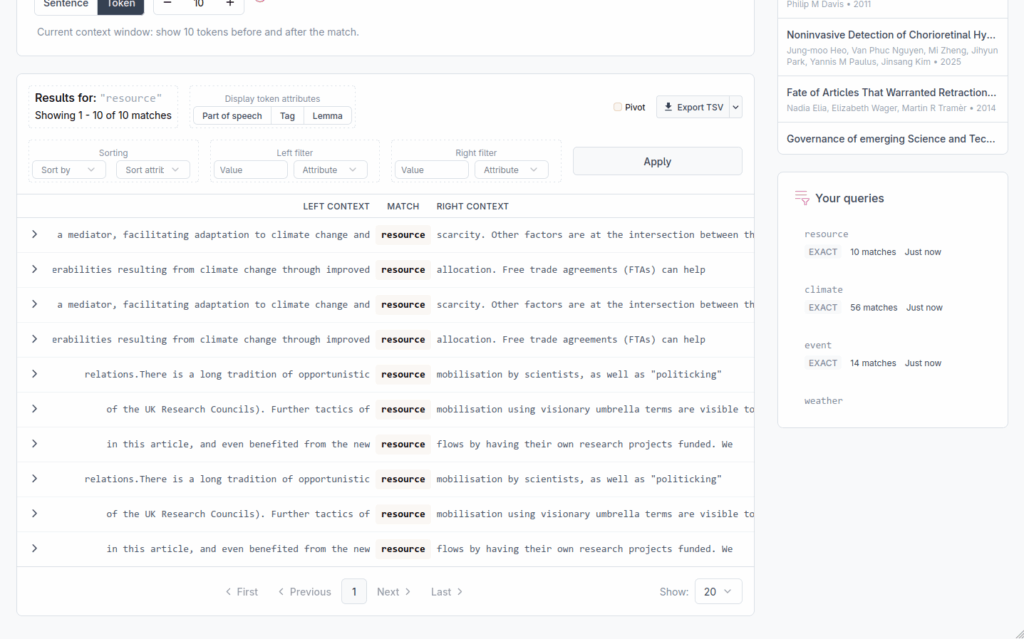
Concordancer

Data formats
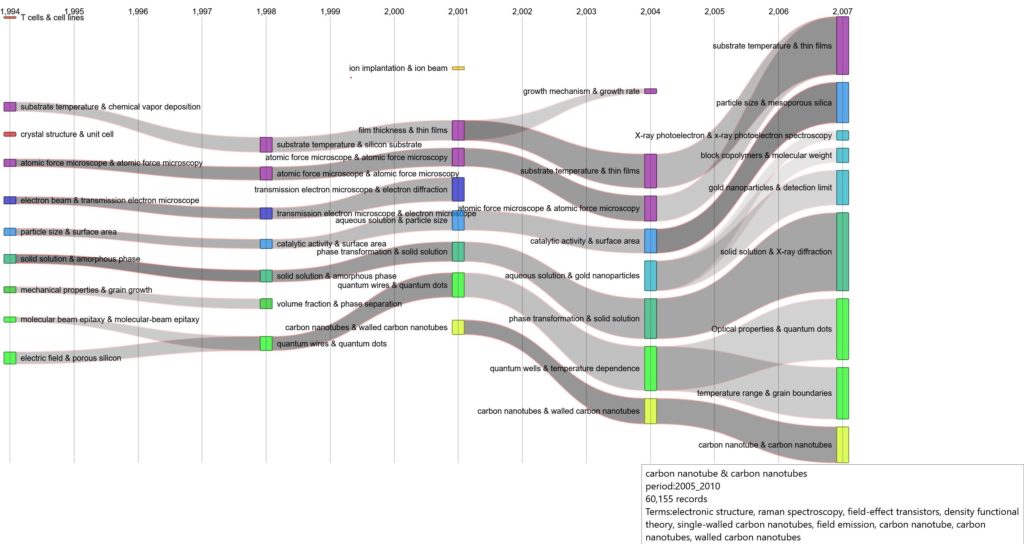
Dynamical Settings
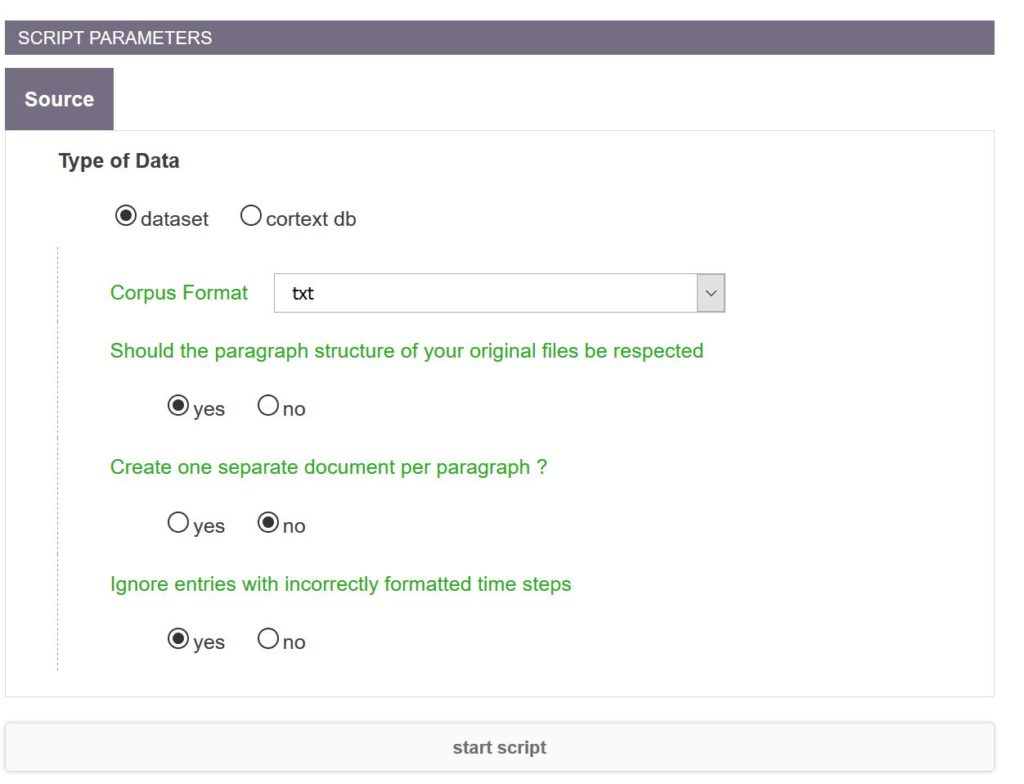
Data Parsing
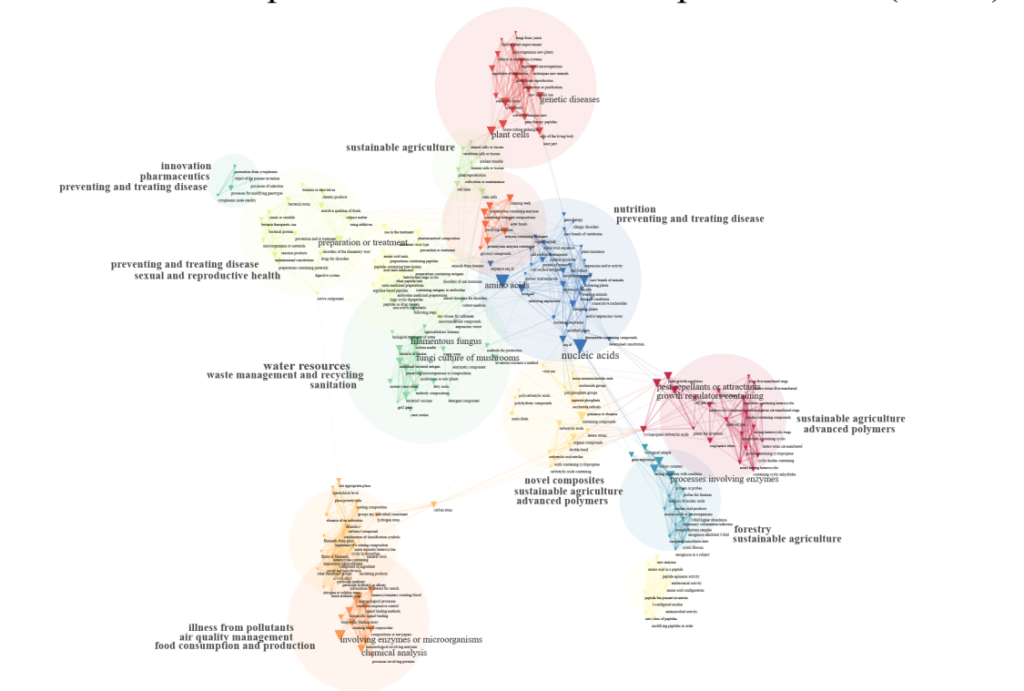
Sdgs And Kets Tagger
 Cortext Manager Documentation
Cortext Manager Documentation