Text processing in CorText is divided in two families whether you are dealing with raw textual content or categorial data.
Lexical Extraction and Term Indexer scripts are deemed to be used with textual content (made of paragraphs or full sentence)
List Builder and List Indexer are rather dedicated to working with data which are single words or expressions like a name, an institution, or any category-like information.
In both cases the Csv Viewer and Editor is instrumental to manage extracted lists.
Text processing documentation

Terms Extraction
Terms extraction automatically identifies terms pertaining to a given corpus. In fact, Natural Language Processing (see supported languages below) tools that we use allow us to identify not only simple terms but also multi-terms (called n-grams). How to use Terms Extraction Textual fields definition Select the textual fields you wish to analyze and index: If...
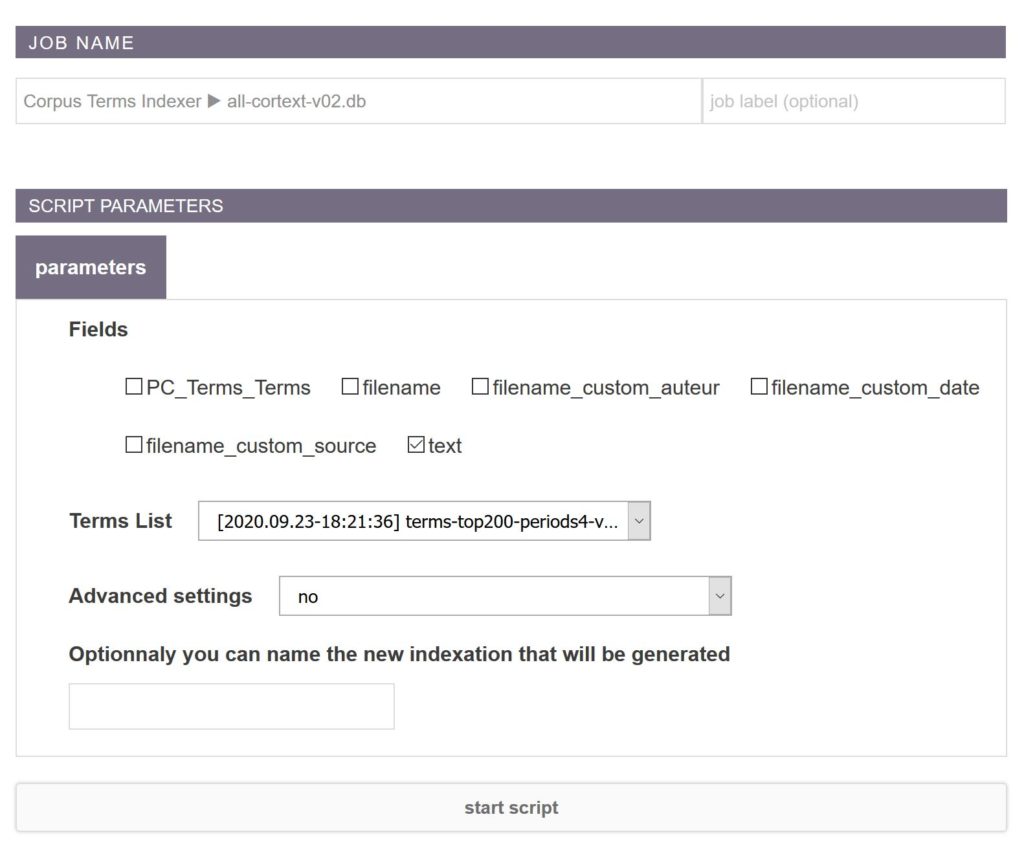
corpus terms indexer
This script works hand in hand with the lexical extraction. Actually, by default, it is even automatically launched every time a lexical extraction is executed. Its basic objective is, given a series of textual fields (provided by the user), to index every term found in a given term list tsv file (specified by the user)...
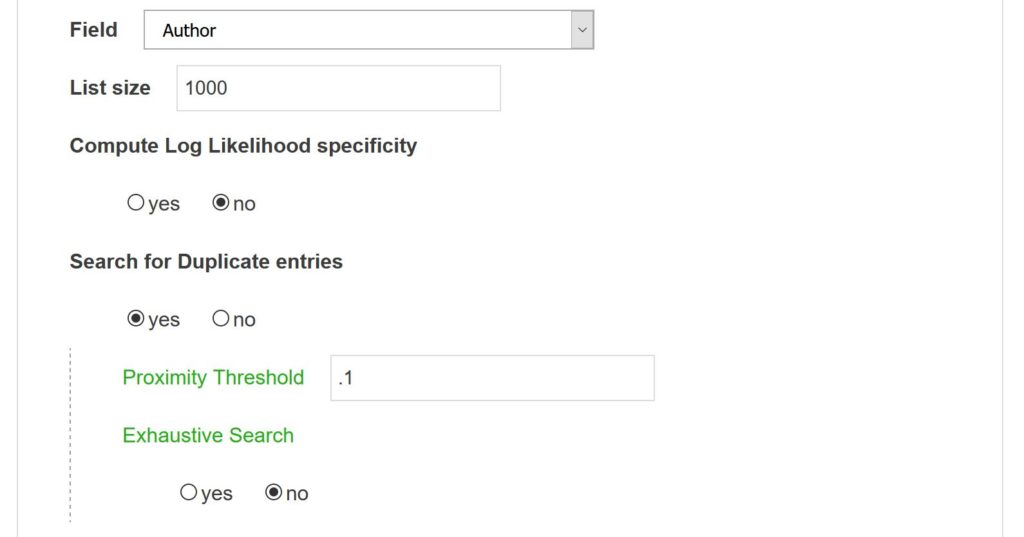
list builder
List builder helps you manage categorial entities. Not only does it provide lists of most frequent textual entities for a given field but it also creates a list of potentially duplicate entries when raw data are noisy (potentially useful for cited references, names, cited journals, addresses etc.) How to use the script Field Select...
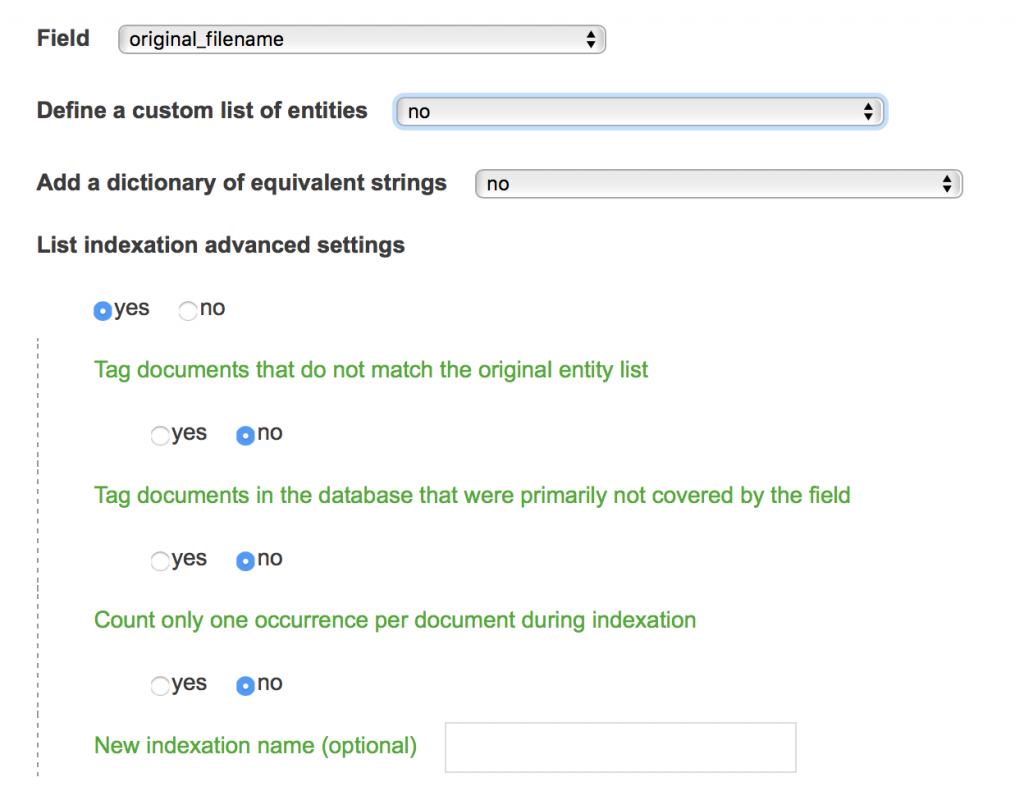
corpus list indexer
This script is naturally connected to list builder script. It provides users with full control other a set of items that may later get mapped or analyzed. Technically, one or several new field(s) will be created using a key defined by user along previously uploaded TSV (csv) files. How to use the script Field Select...
Named Entity Recognizer
The script is based on Named Entity Detection capacities offered by spaCy. NER entity types It allows to identify and index persons, places, organizations, etc. At the moment it can handle 6 different languages. In English, one can select among 19 kinds of entities. CARDINAL Numerals that do not fall under another type DATE Absolute or...
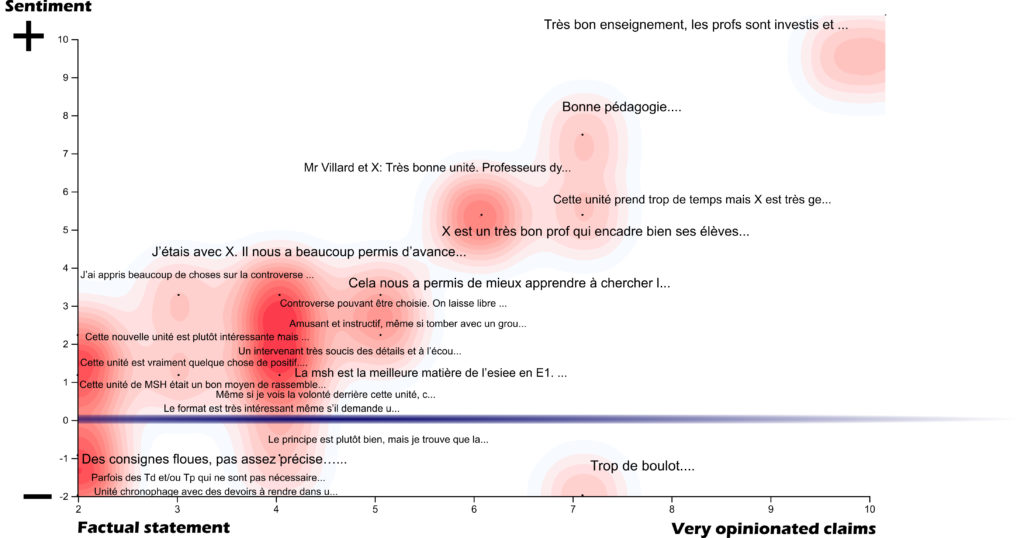
Sentiment Analysis
Sentiment analysis is “the process of computationally identifying and categorizing opinions expressed in a piece of text, especially in order to determine whether the writer’s attitude towards a particular topic, product, etc. is positive, negative, or neutral.” Oxford Dictionary Methods to perform sentiment analysis CorText Manager offers two different ways to perform sentiment analysis. Textblob...
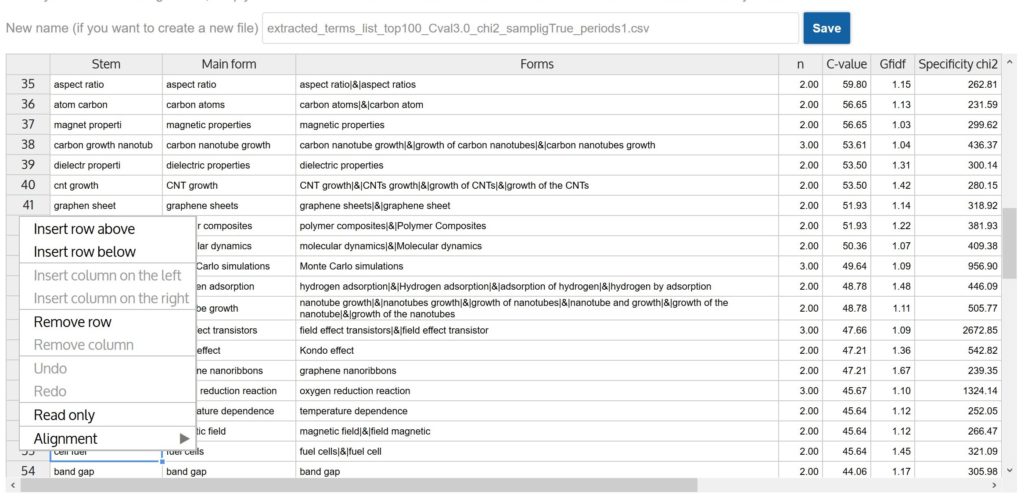
csv editor
A csv and tsv file viewer and editor is generated every time CorText produces a csv (mainly for results) or a tsv (for terms, dictionaries, resources…) file that may require further editing from users, particularly following a term extraction or list building scripts. To access to the interface, simply click on the .csv or .tsv...
Latest questions in the Q&A forum on text processing
129 views0 answers0 votes
613 views2 answers0 votes
1921 views1 answers0 votes
1822 views0 answers0 votes
1821 views1 answers0 votes
1799 views1 answers0 votes
1784 views1 answers0 votes
1923 views4 answers1 votes
1988 views2 answers0 votes
 Cortext Manager Documentation
Cortext Manager Documentation