
List builder helps you manage categorial entities. Not only does it provide lists of most frequent textual entities for a given field but it also creates a list of potentially duplicate entries when raw data are noisy (potentially useful for cited references, names, cited journals, addresses etc.)
How to use the script
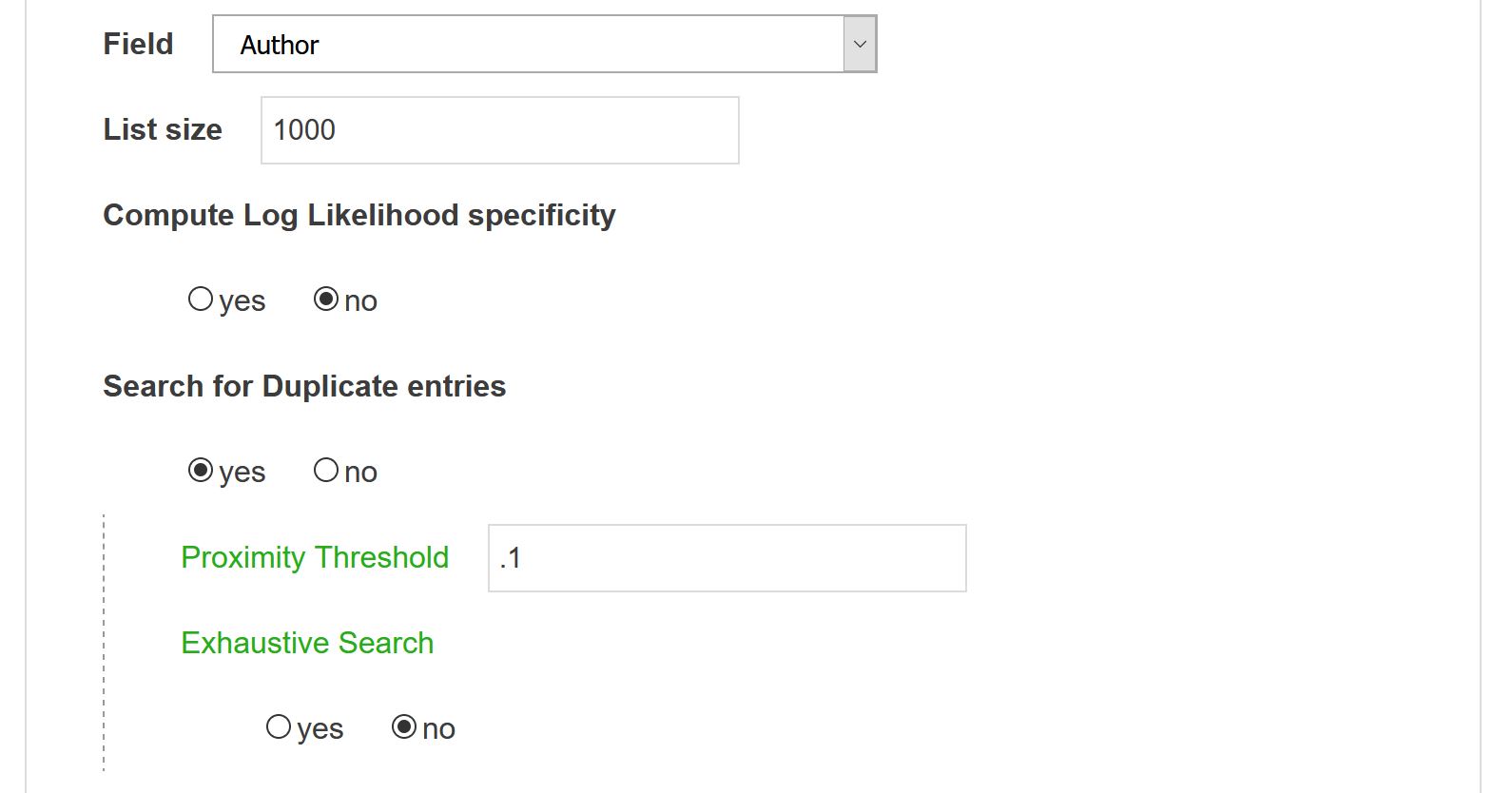
Field
Select the field you wish to focus on.
List size
Only the most frequent items will be extracted
Search for Duplicate entries
First, the set of N most frequent items are selected and exported along with their frequency in a tsv file.
Second, every couple whose string-based proximity is above the threshold will be exported in a tsv file (equivalence file) compiling a wide range of proximity measure: ngram proximity, Levenshtein ratio, word-level proximity measures (inclusion, jaccard, etc.). Some measures may be more adequate according to the field although Levenshtein distance is usually the most pertinent. Item frequencies are also provided to help focus on the most interesting phrases. Note that when applied to isi-based cited references, only references published the same year may be considered as possible equivalent couples.
Proximity Threshold
This setting is necessary for entity normalization. Default value should be fine, but if you feel like some equivalent forms are still missing, you may need to lower this threshold (at the cost of computing time…)
Exhaustive search
By default, two strings are assumed strictly different if they share no common words. If you want to go beyond, you should check the Exhaustive Search option which will extend the search scope.
Clean and (re)index
A tsv editor is also provided to visualize and edit those files directly online.
Once cleaned, those files can be later used in corpus list indexer script.
 Cortext Manager Documentation
Cortext Manager Documentation