This script allows you to query your corpus and build a subcorpus or create new fields with sql-like queries.
Two modes of querying are proposed, sql begin the standard one.
Querying your corpus in a sql-like mode
The principle is to allow users to directly perform sql-like queries on their corpus.
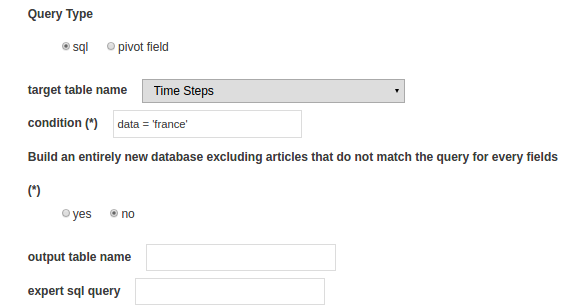
Query type
Choose sql for the sql-like queries mode.
Build a new table
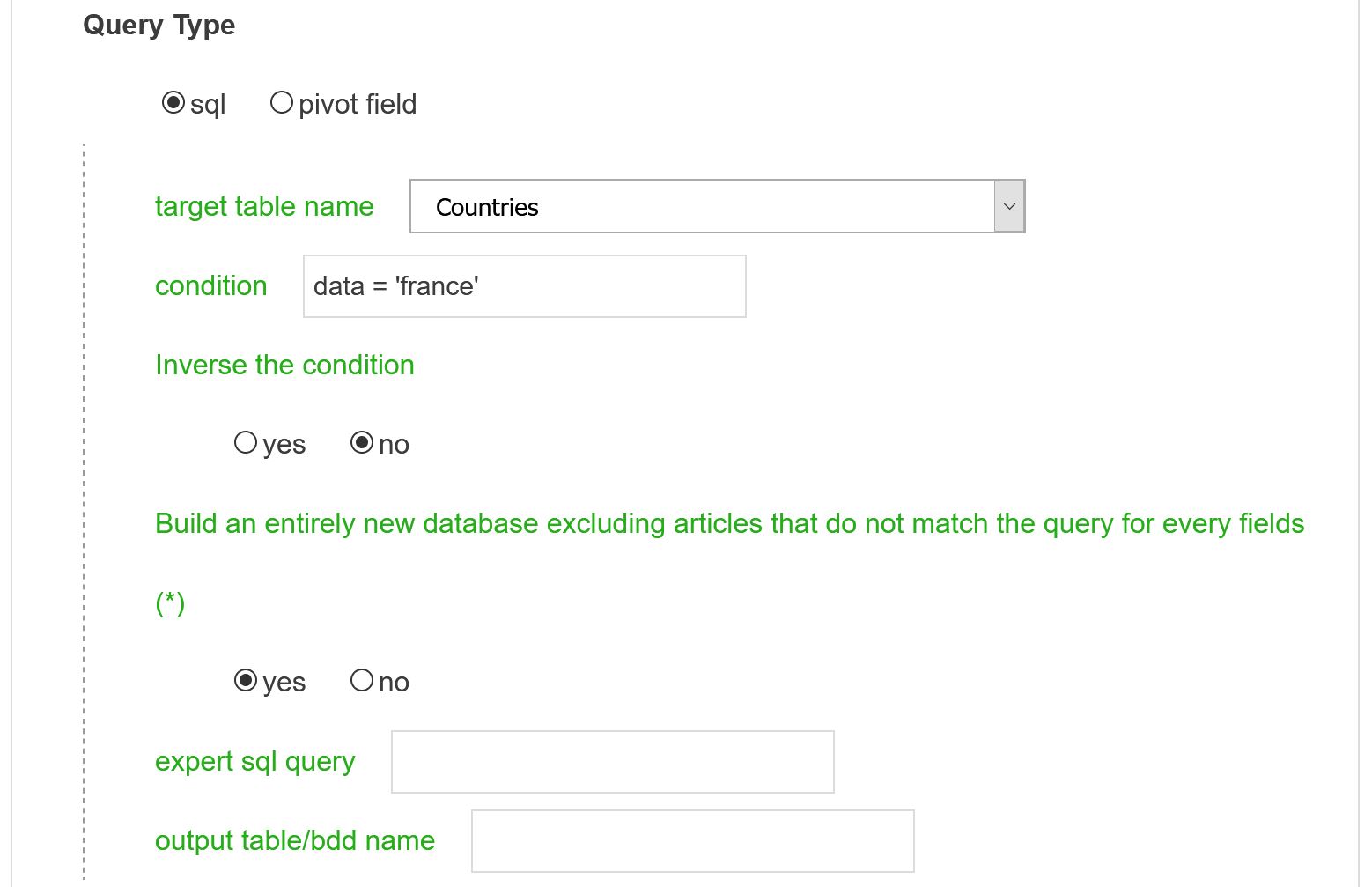
target table name
As illustrated above, one may choose to produce a new table (whose default name will be Countries_custom) from a scientific database which will be a copy of the Countries original table with the constraint that at least one country of publication should be ‘france’. The resulting table can be useful to analyze the ego-network around a given node for instance.
condition(*)
Other example: choosing Keywords as target table and data like ‘%DNA%’ as the condition will isolate articles which keywords include the string ‘DNA’.
When typing conditions, be careful with the type of simple quotes you are using. Only simple straight simple quotes are possible.
Build a new database
It is also possible to build a new database which will only contain documents respecting the given query.
build a new database
For instance, setting Year as target table and data > 2019 as condition while checking the “build a new database” option, will create a new .db file which will only feature documents published after 2019. The newly produced database can then be analyzed normally.
expert sql query
If an expert sql query is filled, the string you enter will be directly applied to your database. You may for instance delete a table you don’t want to use anymore with: drop table ISIterms will delete the table ISIterms
output table/bdd name
Choose the name of the table or the database (depending on the choice made with the option build a new database) which will store the results of the query.
Pivot mode
Query type
Choose pivot field. This query mode is still under development.
 Cortext Manager Documentation
Cortext Manager Documentation