Data curation script is there to help you to handle some transformation you would like to apply to your corpus.
Database level
Rename a Database
Rename your corpus/database with a new name. Useful to shorten database form built by Query corpus which has usually long name.
Remove duplicate entries
This option allows to get rid of duplicate entries in your dataset. Just indicate the variable containing unique keys (typically the index of tweets, or the accession number from articles collected from factiva), and duplicate entries will be erased.
Variable level
Rename a variable
Change the name of a variable in your corpus.
Concatenate variables
Variables to be concatenated, information found in each table will be merged into a single variable. String is for text information and concatenates all the selected texts in one bigger text for each document. String parameter works well to merge Titles and Abstract of articles in a new variable. Categories is for categorical entities (categories, which you also be textual), and concatenates all the lists of values in one new variable. The lists are kept. Categories works well to merge for example articles authors and cited authors.
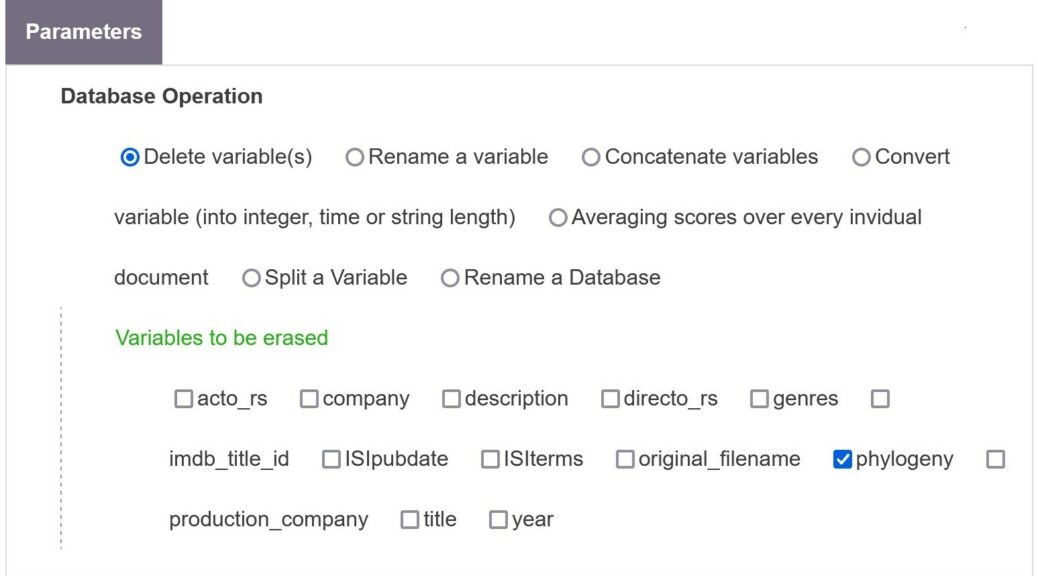
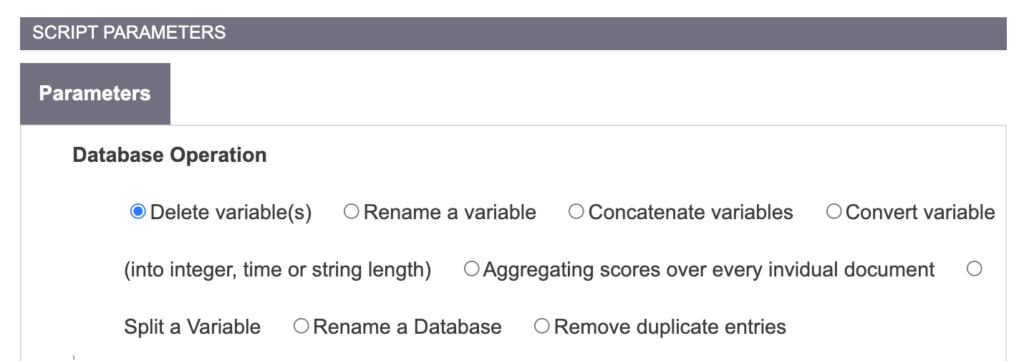
Delete variable(s)
Clean and delete some unwanted variables of your database.
Value level
Convert variable
Convert variable into integer, time or string length. For Integer float will be converted to their integer values and it is possible to apply a coefficient to multiply your values. For length, a length of strings will be returned. And for time a new variable is added, ISIpubdate which is crucial to compute temporal analyses on CorText Manager (e.g. dynamical network analysis, time processing scripts…).
Aggregating scores over every individual document
Compute an aggregate score for each document based on the possible values a variable has in each document. The score can be a sum or the mean of all values (rounded to the smaller integer).
Split a Variable
Split values of a variable based on a specific character (e.g. , or ; …) or string. If no name is added, the resulting table name will be suffixed by split.
 Cortext Manager Documentation
Cortext Manager Documentation