After uploading your corpus, the first mandatory step to be able to apply analysis scripts in CorText Manager is to run the “Data Parsing” script. Data parser transforms your corpus in a sqlite database (see “what does the parsing step?” paragraph below for more details about the database structure).
“Data Parsing” script can only process one unique zip file: don’t forget that, whatever the source from which your corpus is derived and its format type, it should first be archived and uploaded into CorText Manager as a zip file (simply zip the original file or the set of original files that compose your corpus into one unique zip file).
For launching “Data Parsing” script, click on the green box that appears after uploaded a zip file: this will automatically open the “Data Parsing” script window. You can also access to the parsing script using the common way: “+ start script” then selecting “Data Parsing”. You will then be asked to explain the nature (origin/format) of your data.
Data parsing parameters
Type of Data
Dataset
Choose this entry if the zip file comes from one of the sources listed in the “Data Formats” section.
In the “Data Parsing” script window, you will then have to precise the source/format from which your original data is derived.
 Data format options when parsing datasets
Data format options when parsing datasets
Depending of the source/format of original data, more parameters will need to be specified (see “Other parameters” paragraph below for more details).
Cortext db
You also have the possibility to integrate your data that are already in a form of a database. In that case, the database should follow the structure supported by CorText Manager (see “Table structure of Cortext Manager database” paragraph below).
Furthermore, at any stage of your project, you have the possibility to upload the database resulting from your dropped corpus created by CorText Manager. This allows you to modify and to refine your data outside the CorText Manager environment (see more details in the “Building the database” paragraph). If the updated sqlite database still follows the structure supported by CorText Manager, you can upload it back again (don’t forget to zip it before) by simply choosing the “cortext db” option in the parsing script.
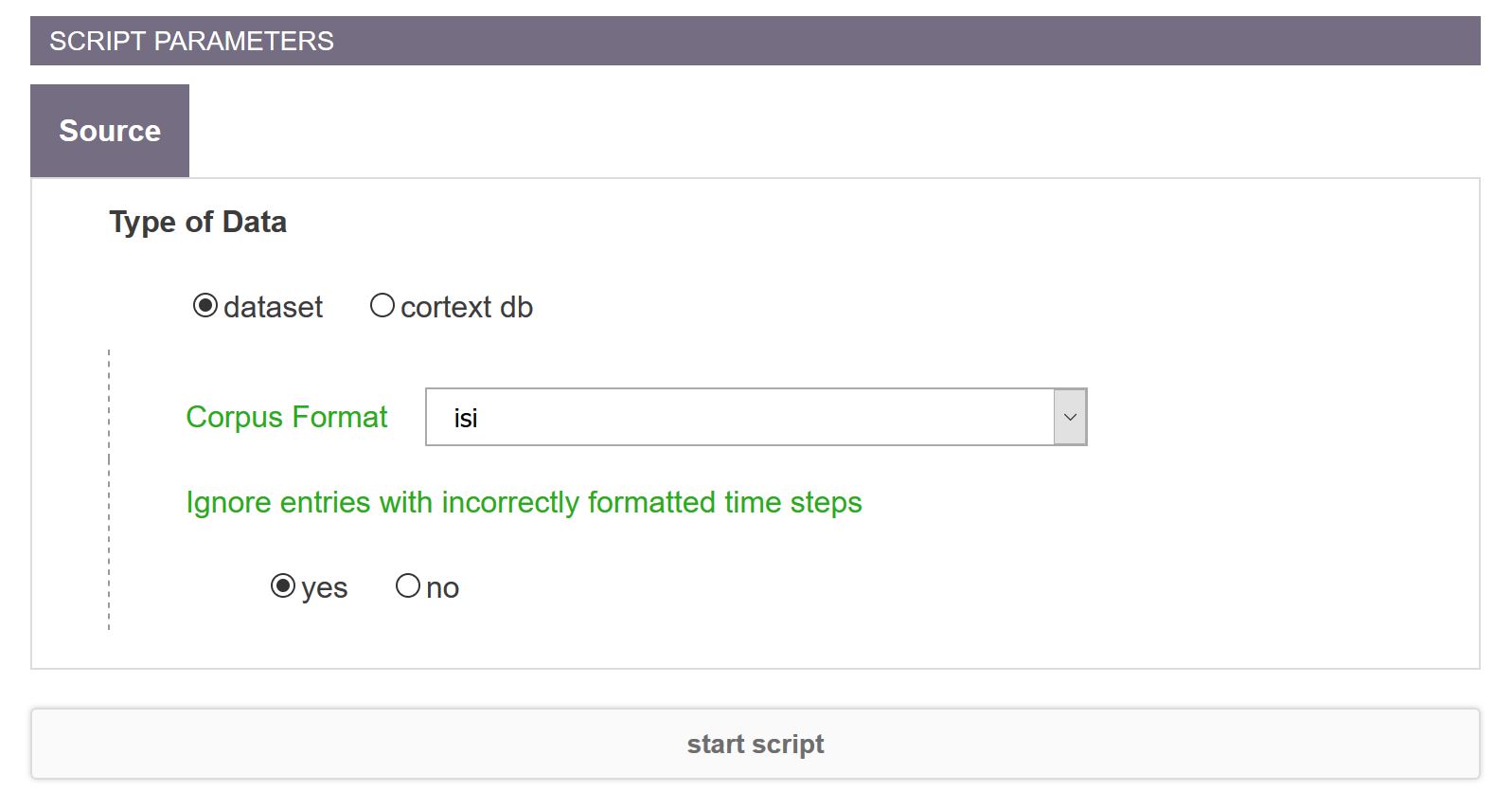
You need also to precise in the “Corpus Format” drop-down menu the data source from which your database is derived (i.e. isi(Web Of Science), xmlpubmed, factiva or other).
Other parameters
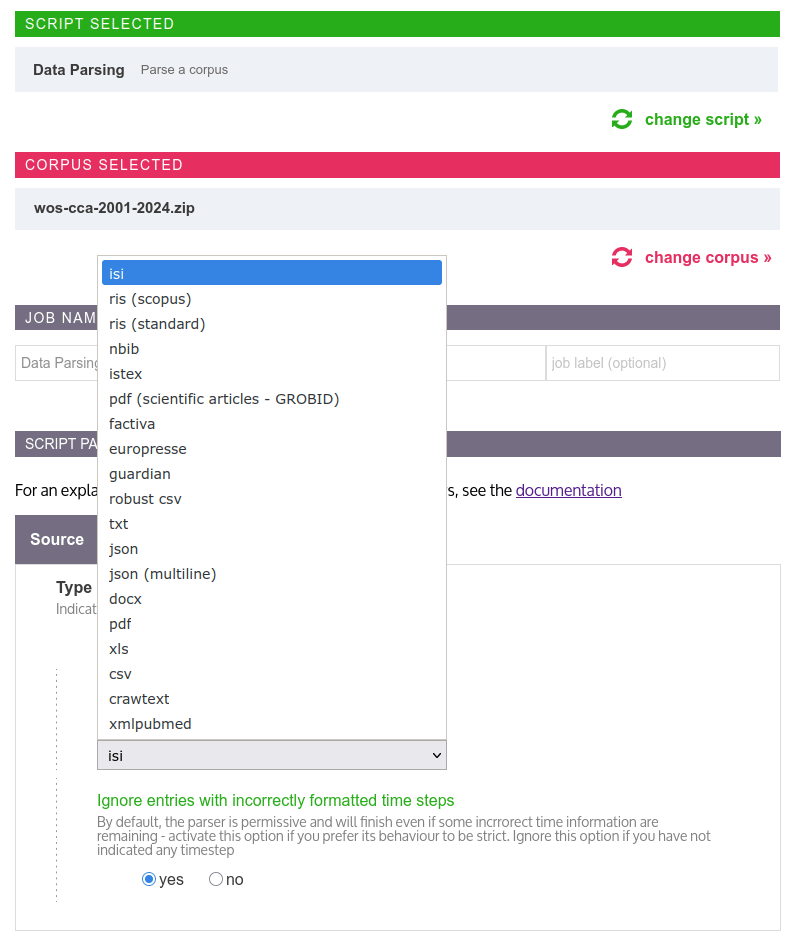
Corpus format
Select the source from which your data comes from or the format of your original files.
Time field
When using the “Data Parsing” script with the entries “robust csv”, “csv”, “xls”, “json” or “json multiline” as “Corpus Format”, you have the possibility to indicate which field of your raw data corresponds to the record timestamps or to a time information. Enter here the name of the variable which contains time information.
After the parsing step, the restructured temporal data will be accessible in CorText Manager in the field named “ISIpudate” (use then this field for doing analyses including a time dimension).
Leave this field parameter empty if you do not have any time variable in your raw data.
Note that for ready-made data sources (e.g. Web Of Science, Scopus, Pubmed, ISTEX, Europress data etc …), time dimension contained in the raw data is automatically recognized and processed by CorText Manager, you don’t need to specify a “Time field” for these sources.
Time granularity and Starting year
This option is present in the “Data Parsing” window in case of “robust csv”, “csv” or “xls” selection as “Corpus Format” and the option “Date Format” selected; in case of “json” and “json multiline” selection as “Corpus Format” ; and in case of ready-made data sources for which exports contain a date format information (i.e. Factiva and Europresse). These parameters allow you to transform time information originally present in a date format into a certain number of years, months, weeks or days since January the 1st of any starting year you define (e.g. if you have a date “2023” in your raw data and define a “Time granularity” as “year” with a “Starting year” at “2000”, the “ISIpubdate” field in the sqllite database will contain the information “23”).
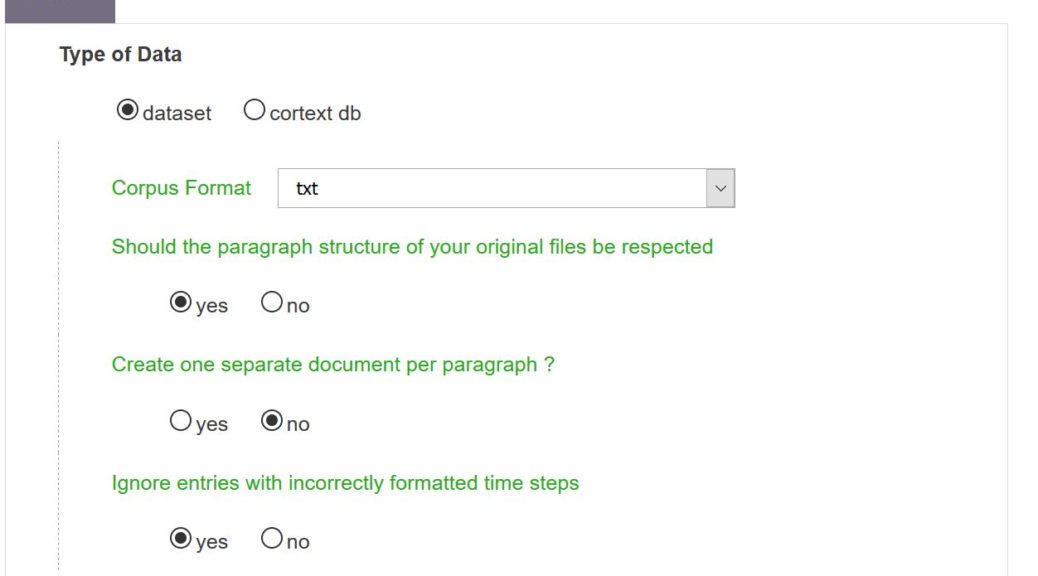
Should the paragraph structure of your original files be respected
This option is present In the “Data Parsing” window only in case of “txt” selection as “Corpus Format”. If you activate this option (i.e. selection of “yes”), the text composing each paragraph present in your txt file will be stored in a different row in the resulting sqlite database (i.e. paragraph 1 will be assigned to Rank 0, paragraph 2 will have the Rank 1 etc … in the “text” table). This means that in your analyses, cooccurrences will only be counted over a paragraph.
What does the parsing step?
“Data parsing” is a generic parsing script that handles all data formats supported by CorText Manager (e.g. txt files downloaded from Web Of Science, RIS files, any file formatted in csv format, xls files from Excel or LibreOffice, a CorText database, etc…). See Data formats section for more details about the correct formatting of data coming from different sources/formats.
Building the database
As output, “Data Parsing“ produces a sqlite database. The database file is accessible via the entry created in the dashboard (file suffixed by a .db) and is also listed/accessible in the “datasets” section on the left-hand side of your project dashboard.
Note that you can have several databases in one project.
At anytime, the sqlite database can be downloaded as a single file which can be easily read outside CorText Manager (with the firefox/chrome plugin sqlite manager, sqlite studio, freely accessible tools like DBBrowser or DBeaver or directly in R and Python…). If needed, you can also refine the data of the sqlite database outside CorText Manager. This updated sqlite database, if still follows the CorText Manager data structure, can be uploaded back (after having zipped it) by simply choosing the “cortext db” entry as “Type of Data” in the “Data Parsing” script.
Table structure of Cortext Manager database
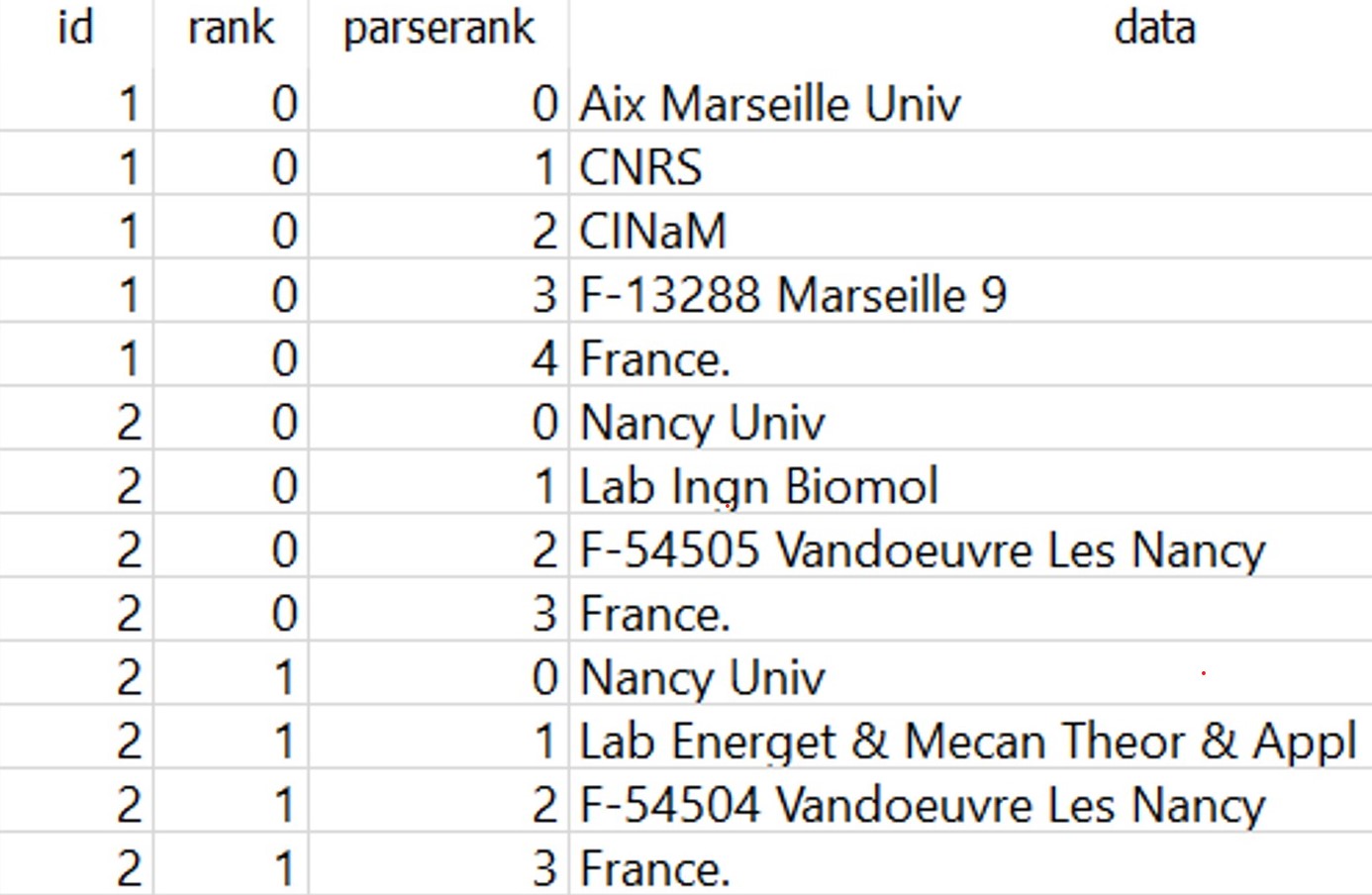
By restructuring your corpus into a database, all variables extracted from your corpus is split into different tables. Each table is structured in the same way and contains the fields: file (i.e. the name of the database), id, rank, parserank, data. The table is named by the name of the variable.
It enables you to run nearly all scripts on all variables (limited only by the data type), and to build in a very flexible manner heterogeneous analyses.
CorText Manager will automatically assign a unique “id” to each document or record that forms your corpus (e.g. a scientific article, a txt file, each row of your csv file). Each table in your database contains this “id” field: it allows you to identify to which document/record the information contained in the table belongs. It is also the field that allows you, if necessary, to link the information contained in the different tables.
The information corresponding to the variable considered is contained in the “data” field of the table. This field will play a core role in the analyses run with the scripts.
“rank” and “parserank” fields are useful in case the parsed information of a variable inside a document/record (i.e. an “id”) contains more than one value (e.g. author addresses for a scientific article). For this “id”, the “rank” will increase.
For some variables (mainly from the Ready-made data sources), CorText Manager will pre-process the information. It is the case for authors’ addresses or Cited References, where strings are cut using comma. In those cases, the “parserank” will increase.
Available variables in the CorText Manager database
Most of the analysis scripts that you will run on your database will also generate data. These outputs will be added to your database by creating new tables (e.g. when running a network mapping script, a new table will be created providing the assignation of your data in the network’s clusters – table for which the name begin by PC for “projection_cluster”). These new tables are structured in the same way as those resulting from the extraction of the variables contained in your raw corpus and will then let you the possibility to launch other analysis scripts using these outputs.
You also have the possibility to import various resources (e.g. external dictionary…, see Upload resource page for more details) and to index your corpus with it. The information will then be added to your database, always following the same table structure.
To sum up, tables in CorText Manager database can contain the information resulting from:
- raw variables: directly parsed from the data source, without any change;
- pre-processed variables: information extracted, divided and cleaned by the parser, from the raw variables;
- calculated variables: built from results after running CorText Manager analysis scripts;
- resources added by users: variables added by users (e.g. edited lists of terms, external dictionaries, added metadata using a tsv or a csv).
Table names are deduced from the names of the variables contained in your original data or can be determined automatically by the “Data parsing” script for the pre-processed variables in case of ready-made data sources (e.g. Web Of Science, Pubmed…).
For databases resulting from most of the data sources (e.g. from Factiva or from your own custom csv files), you will find all theses names in the field/parameter drop-down menus or the checkboxes. For some ready-to-made sources (e.g. Web Of Science, Pubmed), only useful variables and simplified names will be accessible in the analysis script parameters windows.
Variable names to avoid in your raw data
Whatever the entry format you are using, avoid calling variables or tables with the following names which are protected: Terms, ISITerms.
Due to the SQLite database engine used to store corpora, if a value – or some values – of the selected field is “data“, Epic Epoch will fail. Please see here for more details.
 Cortext Manager Documentation
Cortext Manager Documentation