The script is based on Named Entity Detection capacities offered by spaCy.
NER entity types
It allows to identify and index persons, places, organizations, etc. At the moment it can handle 6 different languages. In English, one can select among 19 kinds of entities.
- CARDINAL Numerals that do not fall under another type
- DATE Absolute or relative dates or periods
- EVENT Named hurricanes, battles, wars, sports events, etc.
- FACILITY Buildings, airports, highways, bridges, etc.
- GPE Countries, cities, states (GeoPolitical Entity). Use our CorTexT geocoding service to locate the extracted geographical entities on the earth, and refine the coordinates (latitude and longitude) with GeoEdit Tool.
- LANGUAGE Any named language
- LAW Named documents made into laws
- LOC (LOCATION) Non-GPE locations, mountain ranges, bodies of water
- LOC_GPE combine LOC and GPE
- MONEY Monetary values, including unit
- NORP Nationalities or religious or political groups
- ORDINAL “first”, “second”
- ORG (ORGANIZATION) Companies, agencies, institutions, etc.
- PERCENT Percentage (including “%”)
- PERSON : People, including fictional
- PRODUCT Vehicles, weapons, foods, etc. (Not services)
- QUANTITY Measurements, as of weight or distance
- TIME Times smaller than a day
- WORK OF ART Titles of books, songs, etc.
4 kinds of entities are automatically retrieved in the 5 other languages:
- LOC: countries, cities, states, mountain ranges, bodies of water (which corresponds to LOC and GPE in English). Use our CorTexT geocoding service to filter and locate the geographical entities on the earth, and refine the coordinates (latitude and longitude) with GeoEdit Tool.
- ORG: companies, agencies, institutions, etc.
- PERSON: people, including fictional.
- MISC
Emojis
In addition to the entity types listed above, the NER script is able to identify and extract Emojis if any, and their descriptions.
And that’s in any language! 🥳
- EMOJI emoji consisting of one or more unicode characters, and can optionally merge multi-char emoji (combined pictures, emoji with skin tone modifiers);
- EMOJI DESCRIPTION Human-readable emoji descriptions.
Parameters
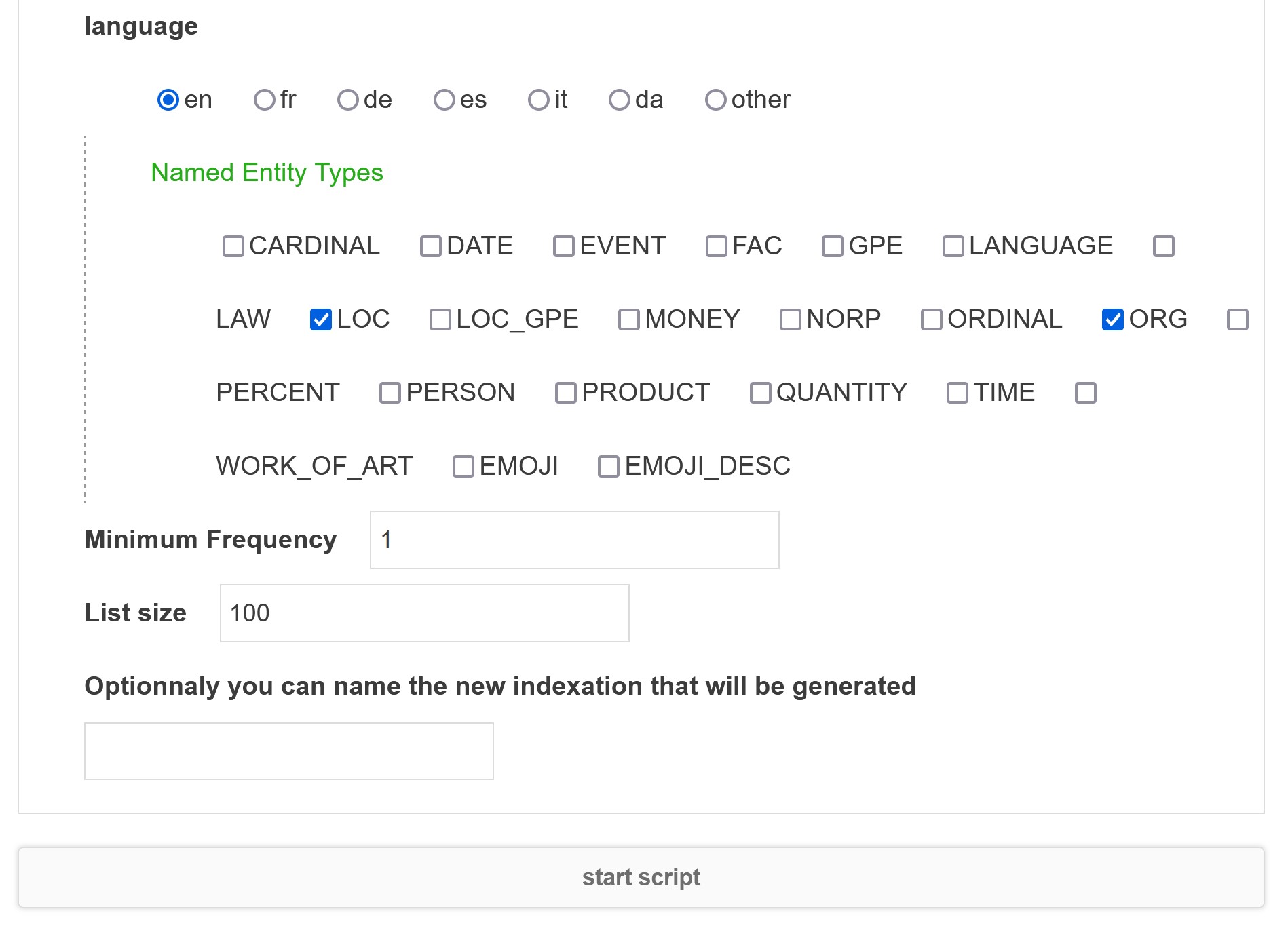
language
Choose the original language of you selected textual field(s).
Named Entity Types
Select the types of entities to extract. See Named Entity Recognizer entity types for the list of extracted entities depending the selected language.
Minimum Frequency
Minimum frequency threshold (applied for each category in each time step).
List size
Total number of distinct entities extracted. Only the N most frequent entities in each category and for each time step.
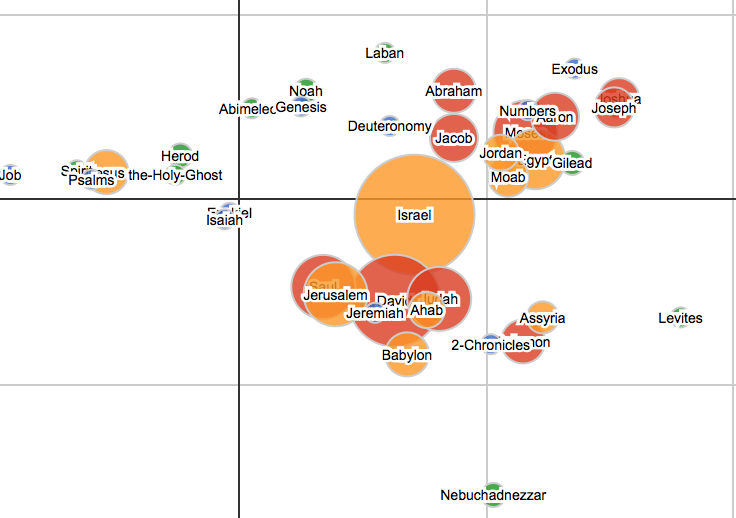
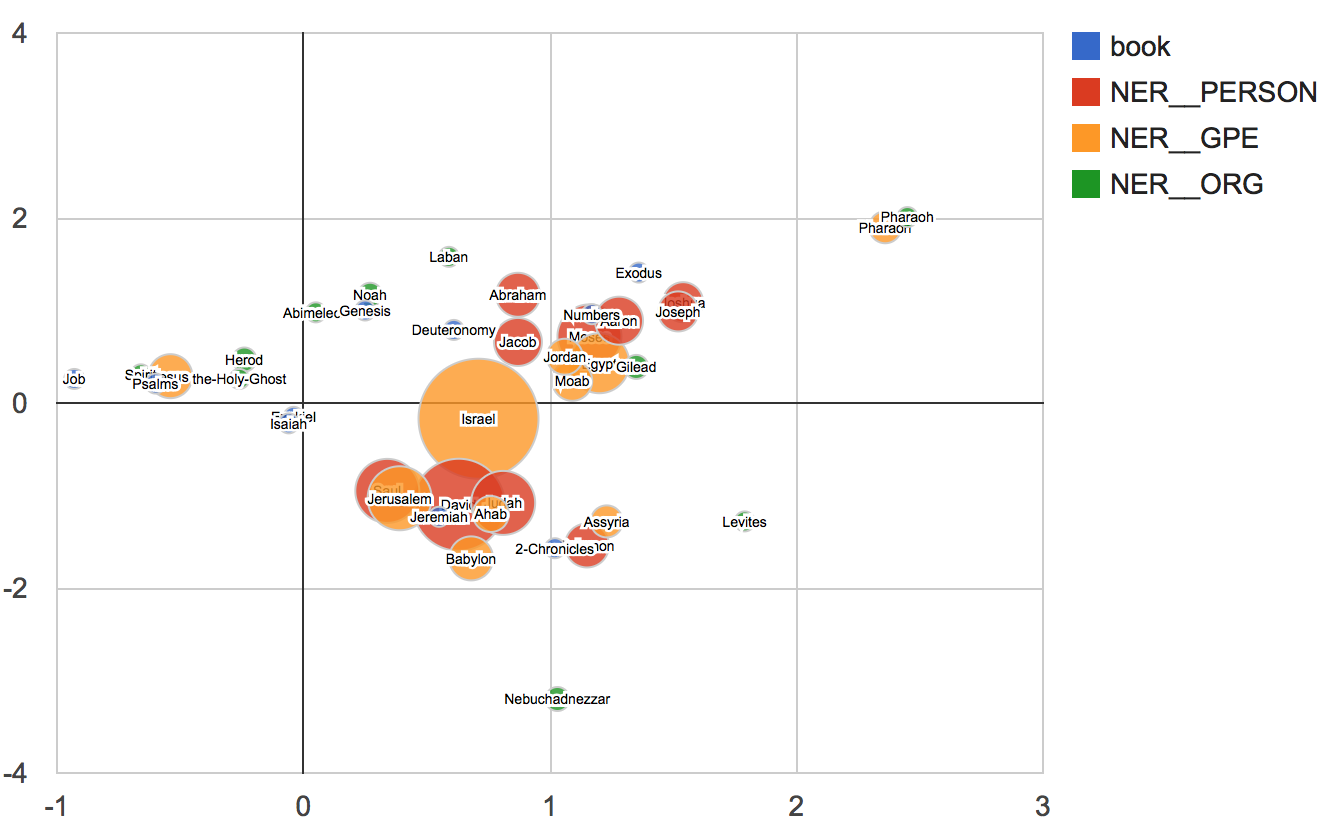
A correspondence analysis as an example
As an illustration, see the result of a correspondence analysis mixing named entities extracted from the bible:
Models and languages
CorTexT Manager NER script is using some specific SpaCy’s trained pipelines.
Where web (en) means that the model has been trained on large datasets of a written web texts (blogs, news, comments), news (fr, de, es, it, da) means that the models have been trained a large dataset of written texts from news and media, and wiki (Multi-language, used when the ‘other’ option is activated) on a small dataset of wikipedia pages.
References
Cite spaCy:
Honnibal, M., Montani, I., Van Landeghem, S., & Boyd, A. (2020). spaCy: Industrial-strength Natural Language Processing in Python. https://doi.org/10.5281/zenodo.1212303
Cite the version of Spacy (v3.3.0) used within the NER script of CorTexT Manager:
Ines Montani; Matthew Honnibal; Matthew Honnibal; Sofie Van Landeghem; Adriane Boyd; Henning Peters; Paul O’Leary McCann; Maxim Samsonov; Jim Geovedi; Jim O’Regan; Duygu Altinok; György Orosz; Søren Lind Kristiansen; Lj Miranda; Daniël de Kok; Roman; Explosion Bot; Leander Fiedler; Grégory Howard; Edward; Wannaphong Phatthiyaphaibun; Yohei Tamura; Sam Bozek; murat; Ryn Daniels; Mark Amery; Björn Böing; Bram Vanroy; Pradeep Kumar Tippa. (2022). explosion/spaCy: v3.3.0: Improved speed, new trainable lemmatizer, and pipelines for Finnish, Korean and Swedish (v3.3.0). Zenodo. https://doi.org/10.5281/zenodo.6504092