
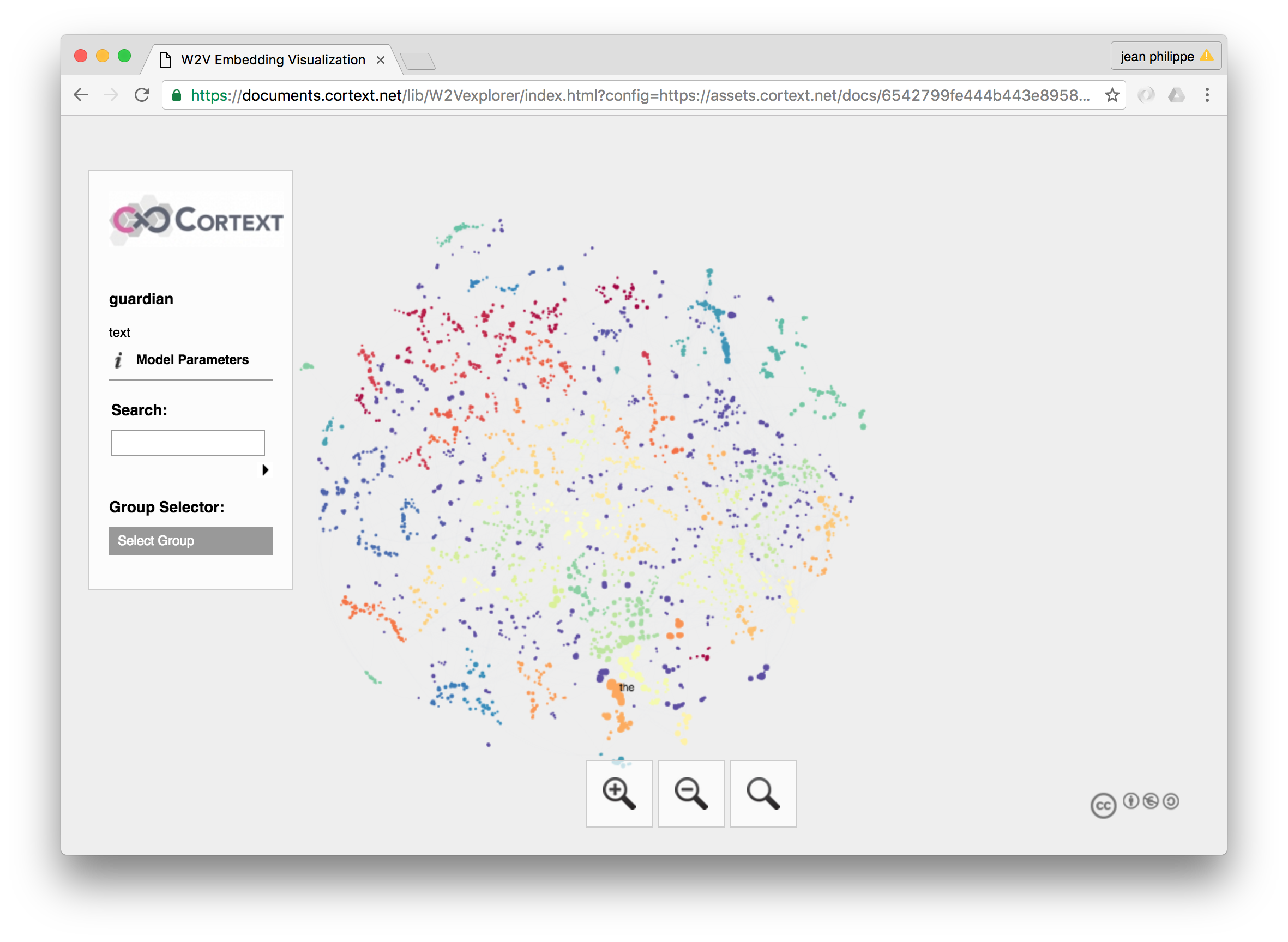
W2V Explorer learns the word embedding of every word (above a given frequency threshold) using the Word2Vec (Mikolov et al. 2013) model in a corpus and visualizing the position of words in a reduced 2 dimensional space generated by t-SNE (Maaten, 2008). Words are also clustered according to their proximity using HDBScan algorithm (Campello et al. 2013).
Set up word2vec
Word Embedding Model
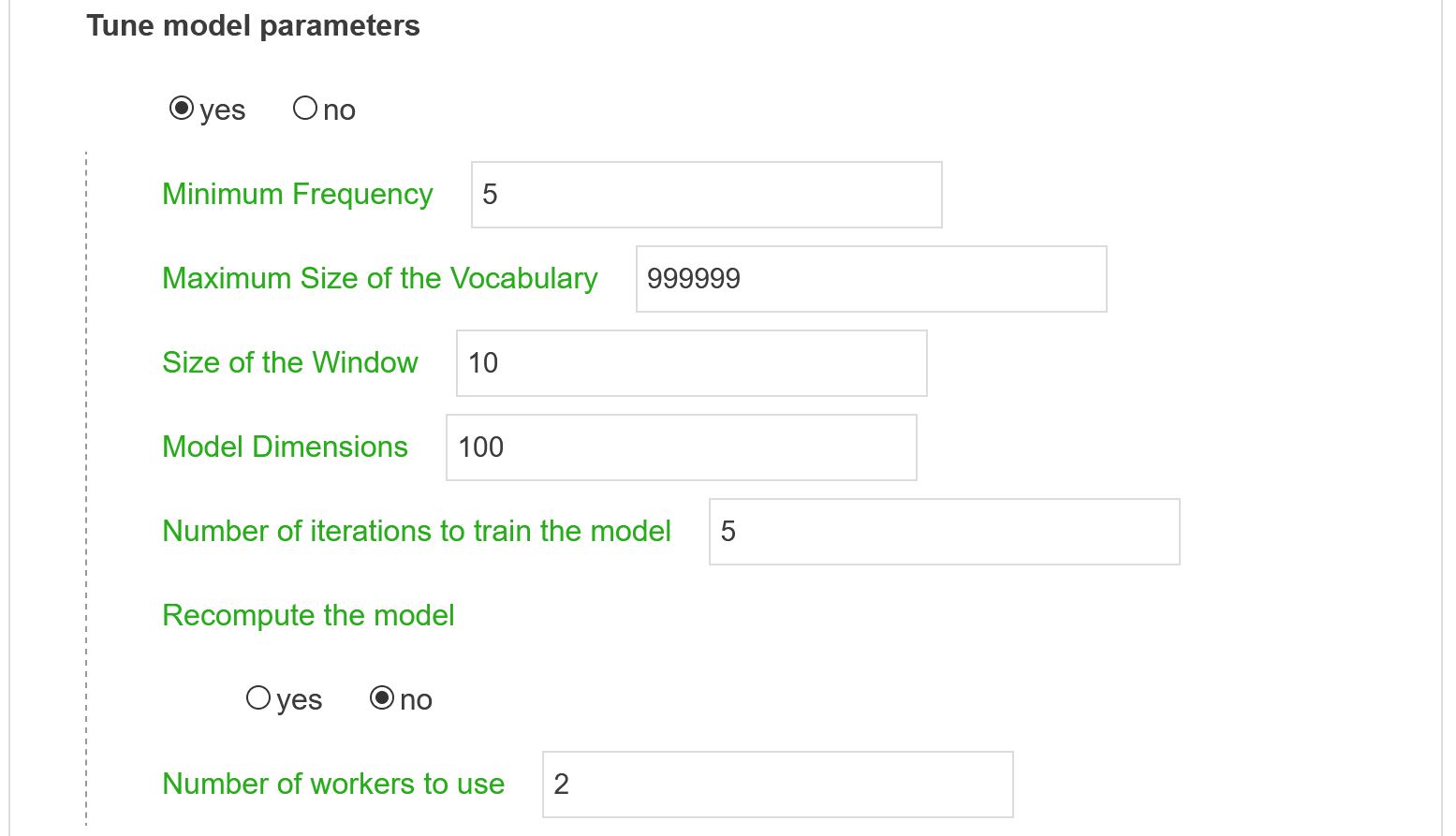
Setting model parameters (gensim (Rehurek & Sojka, 2010) implementation of Word2Vec is being used) like window size, vocabulary size, number of iteration, etc. Note that the model is stored once computed. Restarting the script with the same textual and model parameters will make use of the already trained model (and be much faster…).
Text Processing Method
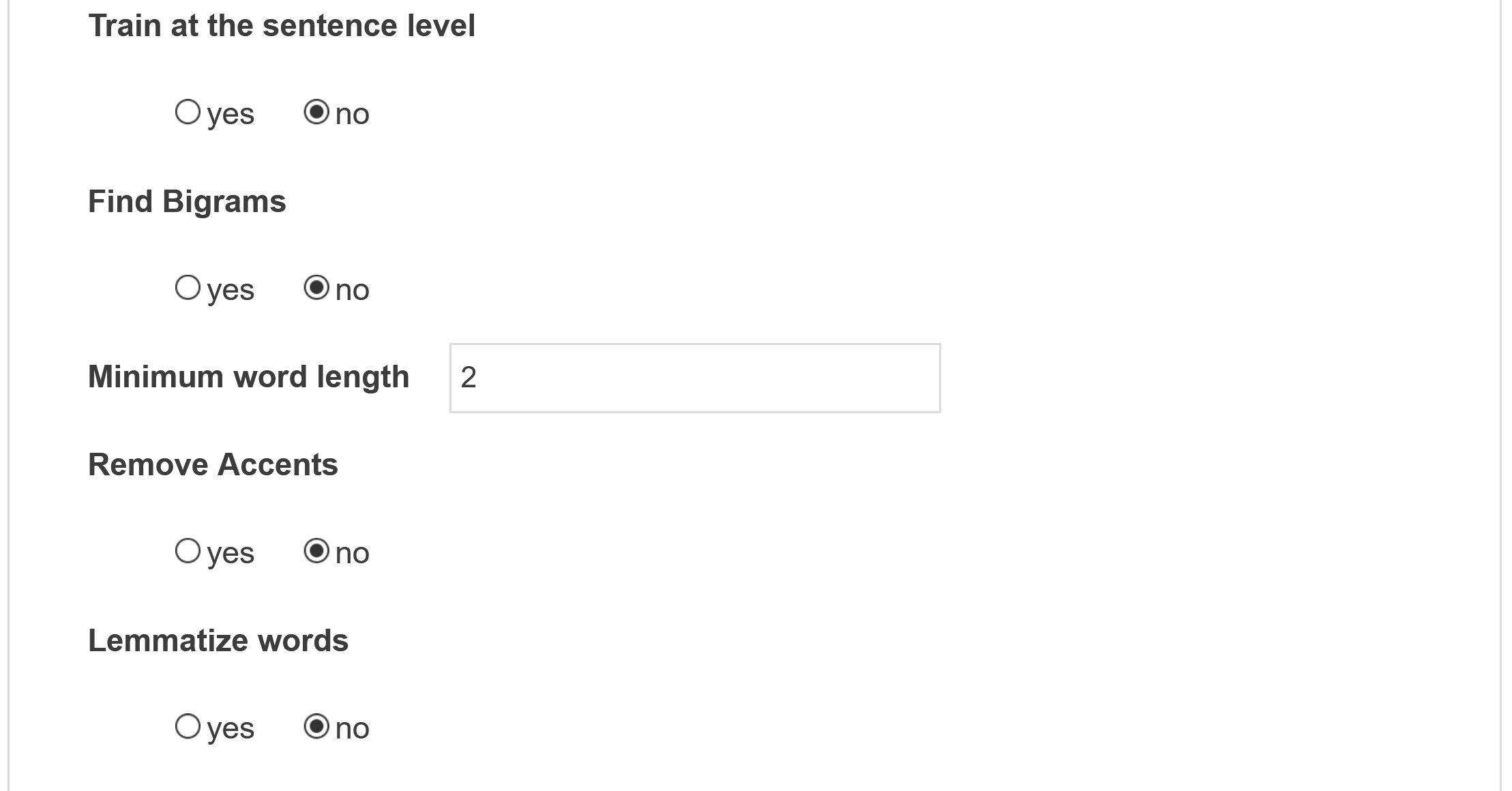
Defining various textual processing parameters: stemming, bigrams, etc. Be aware that stemming only works for English.
Visualization
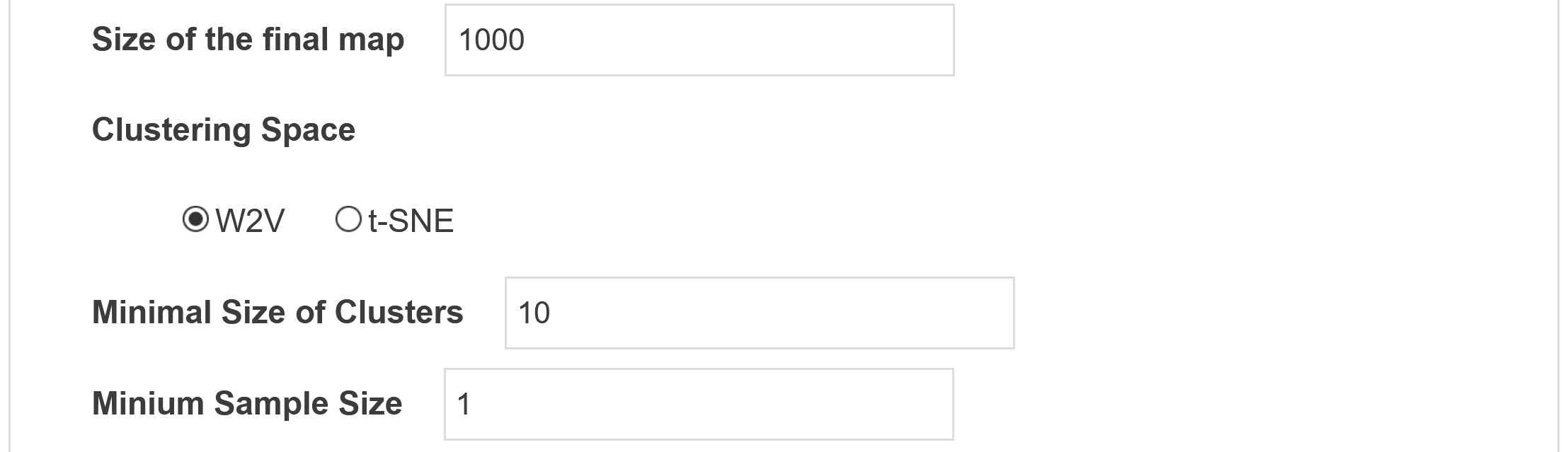
Tuning clustering: defining the minimum size of clusters, choosing the space of clustering (either the original W2V space using cosine distance, or the resulting t-SNE 2d projection using euclidean distance).
Navigate and visualize
The interface allows to browse the final embedding using panning and zooming functions, highlighting the various clusters (labelled by the two most central words), investigating most similar words to a given word when hovering or selecting a word.
Although results are not network per se, the interface is making use of sigma.js plugin. More precisely the web interface was adapted from the Sigma.js explorer plugin for gephi developed by Scott A. Hale, Joshua Melville, and Kunika Kono at the Oxford Internet Institute.
References
Mikolov, Tomas, et al. “Efficient estimation of word representations in vector space.” arXiv preprint arXiv:1301.3781 (2013).
Maaten, Laurens van der, and Geoffrey Hinton. “Visualizing data using t-SNE.” Journal of Machine Learning Research 9.Nov (2008): 2579-2605.
Campello, R. J., Moulavi, D., & Sander, J. (2013, April). Density-based clustering based on hierarchical density estimates. In Pacific-Asia Conference on Knowledge Discovery and Data Mining (pp. 160-172). Springer Berlin Heidelberg.
Rehurek, Radim, and Petr Sojka. “Software framework for topic modelling with large corpora.” In Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks. 2010.