The SDGs and KETs Tagger script automatically classifies textual content, such as publication abstracts, based on predefined categories from:
-
Sustainable Development Goals (SDGs): A set of 17 global goals established by the United Nations in 2015 as part of the 2030 Agenda for Sustainable Development. These goals provide a shared framework for achieving peace and prosperity for people and the planet, with each goal linked to specific targets and indicators.
-
Key Enabling Technologies (KETs): A group of six strategic technologies identified by the European Commission as vital for fostering innovation, competitiveness, and sustainable growth in Europe. These include micro- and nanoelectronics, nanotechnology, industrial biotechnology, advanced materials, photonics, and advanced manufacturing technologies.
The tagger can operate using either SDG or KET classification schemes, or a combined mode (ket_sdg) that integrates both frameworks for broader thematic coverage.
This tagging is based on a pre-trained classifier developed by the University of Sheffield through the GATE RISIS-KNOWMAK service ().
The RISIS-KNOWMAK Ontology is a structured classification system developed to support the analysis of research and innovation dynamics. It is used to categorize entities such as scientific publications, projects, patents, and organizations based on standardized vocabularies. The ontology integrates key domains including scientific fields, societal challenges (e.g. SDGs), and technological areas (e.g. KETs), enabling interoperability and comparative analysis across datasets.
Parameters
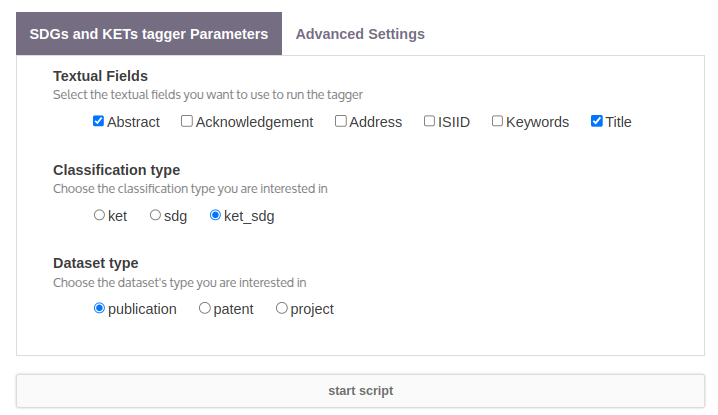
Textual Fields
Select the text fields from your corpus that the tagger should process (e.g., abstracts, titles, etc.).
Classification Type
Choose the tagging category:
-
ket: Key Enabling Technologies -
sdg: Sustainable Development Goals -
ket_sdg: Combines both KET and SDG tagging
Dataset Type
Specify the nature of the documents in your corpus:
-
publication -
patent -
project
Advanced Settings
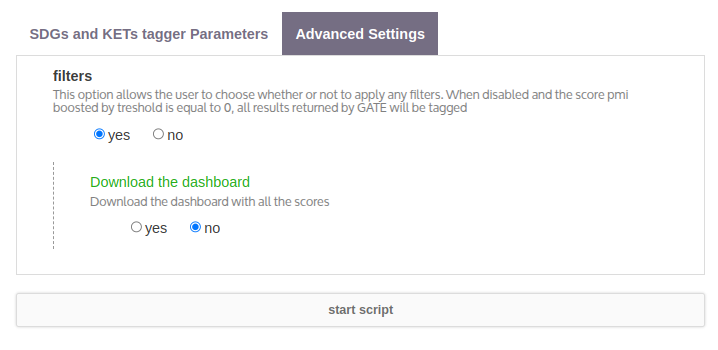
Filters
Choose whether to activate filters:
-
yes: Filters are applied based on PMI (Pointwise Mutual Information) scores and thresholds. -
no: No filtering; all results from GATE will be included.
Download the Dashboard
Choose whether to export the dashboard file with scores:
-
yes: Will generate and download a dashboard file with tagging scores. -
no: No dashboard file will be downloaded.
Output
The result is a tagged version of your corpus, where textual elements (e.g., abstracts) are annotated with SDG and/or KET labels depending on your settings.
If “Download the dashboard” is set to “yes”, a .tsv file containing classification scores and metadata will be available for download.
This dataset provides detailed metrics about the presence and significance of keywords extracted from a set of documents, linked to thematic classes and topics. The scores combine statistical association measures (like PMI) with boosting logic to identify meaningful and distinctive terms across documents and topics.
Column Descriptions
| Column Name | Description |
|---|---|
identifier |
Unique identifier for the document or entry analyzed (e.g., an abstract or publication ID). |
class |
Thematic class or category assigned to the document or keyword, often representing a conceptual domain. |
topicID |
The identifier of the topic (from clustering or topic modeling) linked to the keyword or document. |
unboosted |
Base score of the keyword without any class-specific boosting. Often derived from frequency or statistical association. |
unboosted_pmi |
Pointwise Mutual Information (PMI) score for the keyword without boosting, indicates informativeness. |
Score |
Final score of the keyword, including boosting effects (e.g., class preference or weights). |
Score_pmi |
Final PMI score after boosting, capturing both statistical association and class enhancement. |
boostedBy |
Indicates the class or topic that boosted the keyword. This field remains blank if no boosting occurred. |
diffunboostpmi |
Difference between boosted and unboosted PMI scores, measures the impact of boosting. |
diffsuperclasspmi |
Measures the difference between the superclass-level PMI and the unboosted PMI, if a superclass exists. |
alldiffpmi |
Sum of all PMI differences (boosted vs. unboosted and/or vs. superclass), indicating global significance shift. |
total_keywords |
Total number of significant keywords identified in this class-topic pairing. |
nbclass |
Number of different classes in which the keyword appears, used to assess specificity or dispersion. |
keyword |
The keyword or term extracted and evaluated in context. |
score_keyword |
Statistical score (e.g., TF-IDF or frequency weight) specifically for this keyword in the document/class context. |
textlength |
Length of the document text (in characters) used for normalization or filtering. |
selectorno |
Selection flag or number (e.g., "selected" or "discarded") based on filtering criteria. |
ABSTRACT_TITLE |
Selected textual field (or concatenation of the selected textual fields) of the document used as the source text for keyword extraction. |
avgboostedpmi |
Average PMI score of all boosted keywords in this context, measures global informativeness post-boosting. |
avgalldiffpmi |
Average of all PMI differences for keywords, used to evaluate thematic distinctiveness or semantic shift. |
Measures Used in the SDGs and KETs Tagger
The classification mechanism relies on several scoring techniques to associate text segments (e.g., abstracts, titles) with SDG or KET categories. Below are the main metrics involved:
Pointwise Mutual Information (PMI)
PMI is a statistical measure that evaluates how much more often two terms co-occur than would be expected by chance (Church, K. W., & Hanks, P. (1990)). In this context, it measures the association between a term in the text and a target category (e.g., SDG 7 or KET “Photonics”).
Formula:
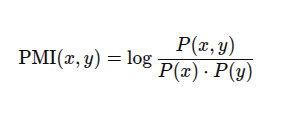
Where:
-
P(x,y) is the probability of co-occurrence between term x and category y
-
P(x) and P(y) are their respective marginal probabilities
Use in Tagging:
-
Terms with higher PMI scores are more strongly associated with a category.
-
The algorithm computes PMI using pre-compiled co-occurrence tables extracted from reference corpora labeled with SDGs or KETs.
Boosted Scores
Boosted scores adjust raw PMI values by integrating contextual, positional, or hierarchical information. This prevents overrepresentation of terms that are frequent but not necessarily discriminative.
Boosting Techniques Include:
-
Keyword Boosting: If a term appears in a manually curated list of “seed keywords” per category, its score is increased.
-
Hierarchy Boosting: A term associated with a subcategory may inherit part of the score from its parent category (e.g., in SDG ontology).
-
Positional Weighting: Terms in the title or the beginning of the abstract may be given more weight.
PMI alone may not reflect importance or contextual relevance. Boosting allows the tagger to emphasize semantically or positionally significant terms.
Core Scores inTagging
The implementation of SDG tagging uses four related measures:
-
Unboosted – Keyword-level frequency relative to text length.
-
Unboosted PMI – Keyword-level PMI between a found keyword and the trained dataset’s keywords.
-
Boosted – Semantic-level frequency, where a keyword’s score is increased when co-occurring with superclass keywords.
-
Boosted PMI – Semantic-level PMI between a found keyword and keywords from the superclass training set.
Both Unboosted PMI and Boosted PMI retain the idea of requiring more than one keyword from a class to appear in the text for selection.
This increases semantic and contextual accuracy, compared to selecting based on a single isolated keyword.
Filter Logic
When filters is enabled, the SDGs and KETs Tagger applies a multi-step SQL filtering pipeline to retain only meaningful and unambiguous keyword–class–identifier associations.
Ensure Sufficient Keyword Support
Create a temporary table to keep only (identifier, class) pairs supported by at least two distinct keywords.
Filter Out Short Documents
Compute total character length of title + abstract and retain documents with ≥ 300 characters.
Compute Specificity Metrics
Keyword-level:
-
Number of associated classes and identifiers.
-
Min/max/avg values of boosted and unboosted PMI scores.
Class-level:
-
Average boosted PMI, unboosted PMI, and superclass PMI for each class (on sufficiently long documents with ≥2 keywords).
Keyword ambiguity:
-
Max difference in PMI scores across classes for each keyword (used to resolve ambiguity).
Apply Final Filtering Rules
In gate_dashboard_selection, we retain a classification if at least one of the following holds:
-
-
The
(identifier, class)has ≥ 2 keywords. -
The keyword is in the manual whitelist (e.g.
"bioinformatics approach","carbon farming"). -
The keyword has ≥ 3 words.
-
The keyword’s PMI scores (boosted or unboosted) exceed class averages.
-
The document is long enough and
keyword_score ≥ 2.
-
We exclude any classification where:
-
-
The keyword is on the blacklist (e.g.
"green","technology"). -
None of the inclusion rules are satisfied.
-
Results are tagged as:
-
-
selectorno = 'selected'if retained. -
selectorno = 'no'if filtered out.
-
🔕 When filters = false
The pipeline skips all filtering steps and all associations are retained.
Use Case: Visualizing Thematic Clusters and SDGs with Network Mapping
After processing your corpus using the SDGs and KETs Tagger script, you can generate a semantic network visualization to explore the distribution and relationships of tagged keywords across thematic areas and Sustainable Development Goals (SDGs).
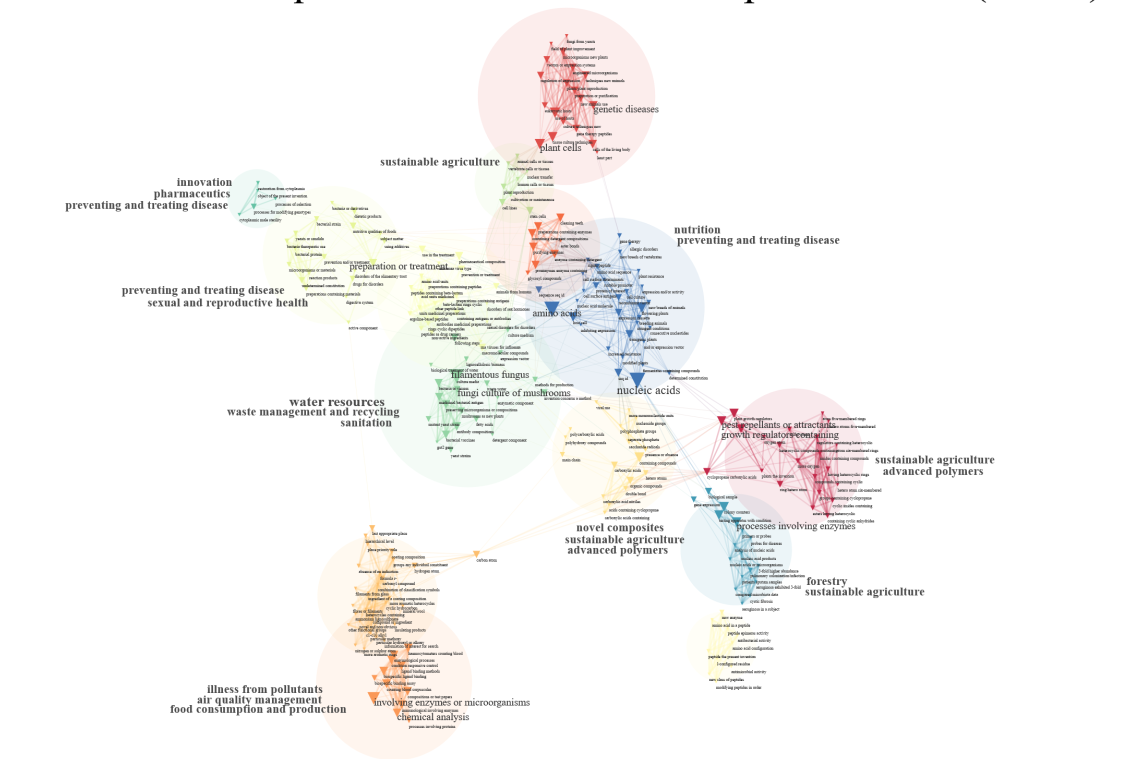
This network graph reveals clusters of keywords that were annotated according to SDG classifications. Each color-coded cluster represents a distinct thematic domain, such as:
-
Sustainable agriculture
-
Pharmaceutical innovation
-
Waste management
-
Nutrition and disease prevention
-
Advanced polymers and materials
-
Air quality and pollutants
In addition, key concepts like “plant cells,” “nucleic acids,” or “enzymes” appear as central nodes. These terms frequently link multiple SDG-relevant themes, thereby highlighting cross-domain relevance.
Thanks to the SDGs and KETs Tagger script, this type of network mapping transforms textual data into a strategic landscape. It guides analysis, fosters insight, and supports decision-making in research planning, funding allocation, or innovation monitoring.
References
United Nations SDG overview: SDGs
European Commission – Accelerating technological change and hyperconnectivity : KETs
Maynard, D., Petrak, J., Song, X., & Funk, A. (2019). Report on Ontologies and Tagging.
GATE Classification Tool – Technical Documentation : RISIS-KNOWMAK GATE Classification
Church, K. W., & Hanks, P. (1990). Word association norms, mutual information, and lexicography. Computational Linguistics
KNOWMAK Report on Ontologies and Tagging – September 2018
This work was partially supported by European Union under grant agreement No. 825091 Horizon2020 Research and Innovation Programme RISIS².