Different tools are provided to help you browse your data:
- First Corpus Explorer provides a table-like visualization of your dataset,
- Demography script is useful for getting an overall idea of the dynamics of entities in each field,
- Distant Reading provides a complete interface for evaluating the temporal trend of textual entities.
- With Word2Vec Explorer, one can browse the structure of large vocabulary trained from a corpus
Data exploration documentation
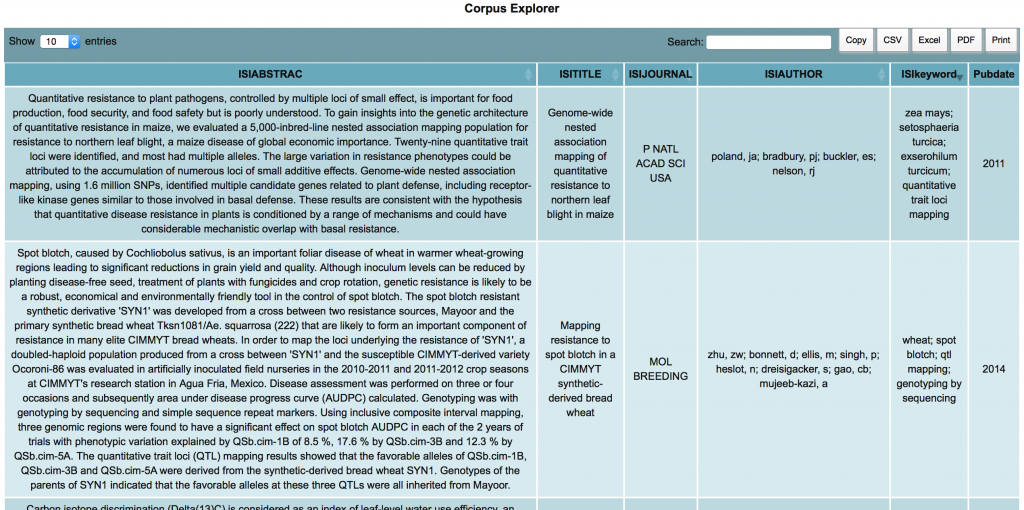
Corpus Explorer
Corpus explorer provides a table-like view of your dataset directly online allowing to directly read the content of your corpus. Different filtering option are also provided either globally using the top search box or for each field using the individual search boxes at the bottom. A column may also be hidden using the Toggle option at the...
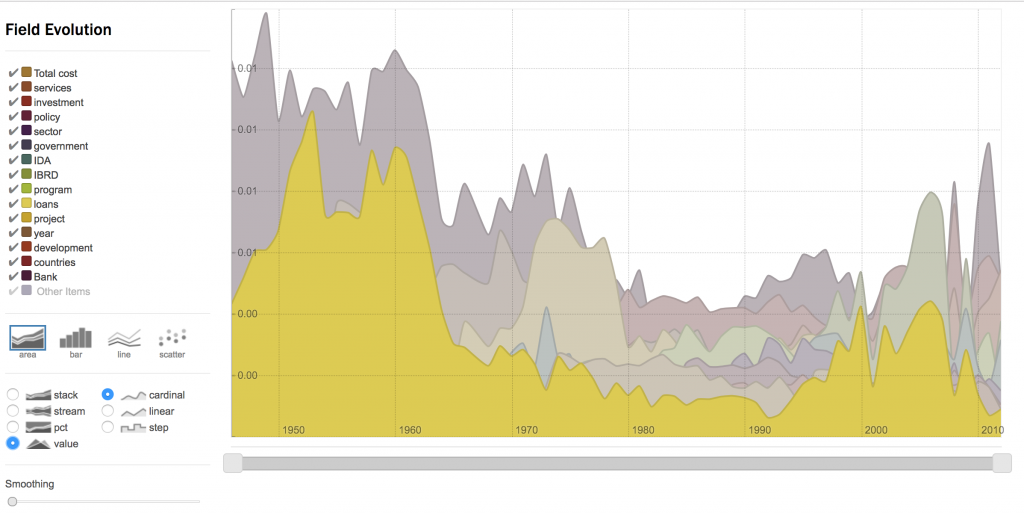
Demography
Demography processes each field of the corpus and counts the raw evolution of occurrences of the top items. You will simply be asked to specify the number of top items you wish to evaluate. If you previously customized periods, you can also optionally choose them instead of the original time stamps. The script creates two...

Distant Reading
Inspired from Franco Moretti work on literary corpus, this script provides a complete interface (files suffixed by distant.html in the resulting dataset directory) for comparing the dynamics of a series of items in a corpus. It is mainly designed to compare words from a given textual field but could be used for other purposes… Distance reading parameters Textual...
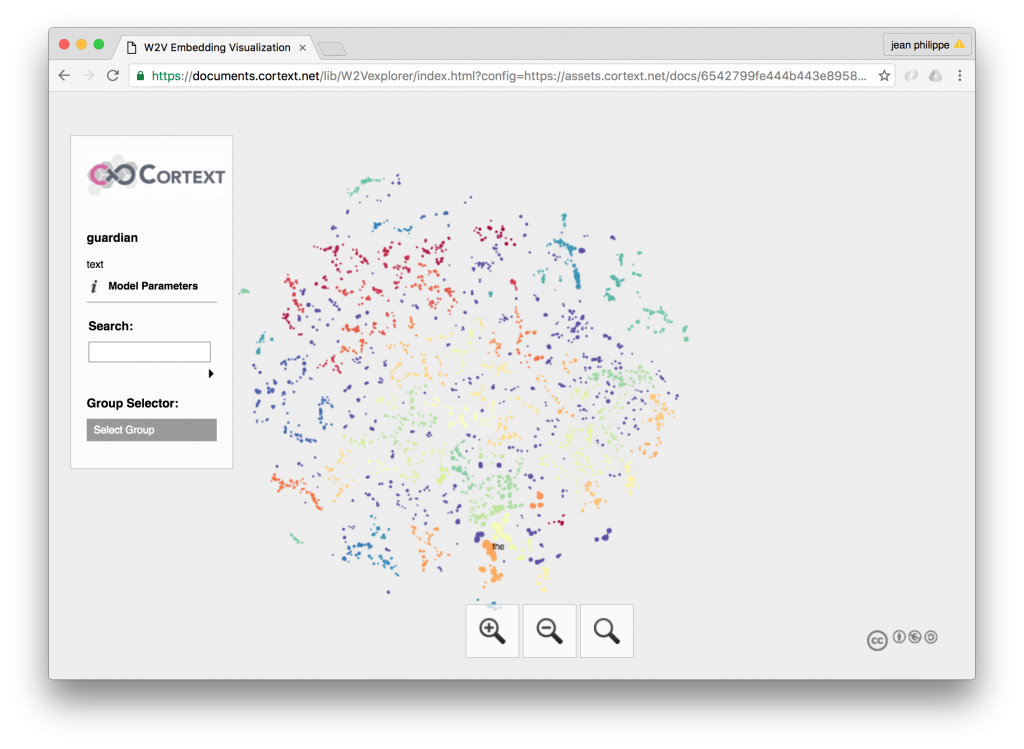
W2V Explorer
W2V Explorer learns the word embedding of every word (above a given frequency threshold) using the Word2Vec (Mikolov et al. 2013) model in a corpus and visualizing the position of words in a reduced 2 dimensional space generated by t-SNE (Maaten, 2008). Words are also clustered according to their proximity using HDBScan algorithm (Campello et al. 2013). Set...
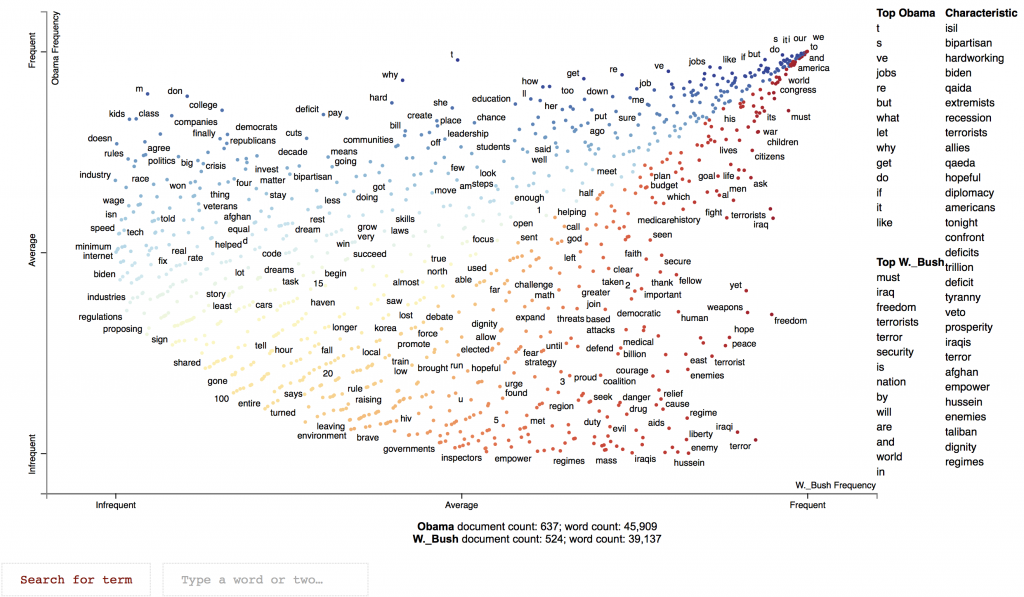
Contrast Analysis
Contrast Analysis script proposes to show how much two sub-corpus (defined by the user within a dataset) feature a different set of words in its textual content or entities in any categorical field. It uses the excellent library scattertext (Kessler J.S., 2017). See below an interactive example showing which words were used relatively more often...
Latest questions in the Q&A forum on data exploration
1843 views1 answers0 votes
1839 views1 answers0 votes
1915 views0 answers0 votes
1488 views0 answers0 votes
1563 views1 answers0 votes
1646 views1 answers0 votes
1511 views1 answers0 votes